Channels
Initially, I developed this so I can easily switch between different Attention mechanisms for my Small Language Model (SLM) experiments and benchmarking. However, I also realized that these implementations can be applicable in Computer Vision, modernize Vision Encoders, RL, and others. I hope this helps researchers, students, or educators in general. I also included MiniMax M3's sparse attention. This can be integrated with Andrej Karpathy's autoresearch framework. For contributing: I encourage you to please open a PR. I would like to see and learn implementations of other attention mechanisms I haven't covered in this repo. Thank you! GitHub Link: submitted by /u/AnyIce3007 [link] [Kommentare]
I'm running into an issue with an ablation study for a paper I'm preparing. I trained a model. The model achieved my best result, and I saved the trained checkpoint (.pth file). Now my supervisor wants me to perform an ablation study by removing components and how it impacts the accuracy. My concern is that if I retrain from scratch, the accuracies will not exactly match the original run due to randomness, different seeds, etc. is there any way i can do the ablation study without retraining? I'd appreciate hearing how others have handled this situation in publications or thesis work. please help me out submitted by /u/Plane_Stick8394 [link] [Kommentare]

Kalshi and Polymarket have enlisted hundreds of paid influencers to spur interest in everything from sporting events to political races.

For health hackers, the risk is not experimenting.

In this post we look under the hood of BrightData's SDK and how it turns ordinary consumer TVs into exit nodes of an enormous commercial, residential proxy network leveraged by the AI industry to scrape web data and train language learning models.

In line with Project 2025, over 900 deep-sea sensors are being removed from the ocean floor, cutting off data used to track climate change

Contribute to timothygao8710/minWhisper development by creating an account on GitHub.

Build dynamic workflows from simple HTTP stages. Schedule execution, persist state, inspect every stage, and control workflows from the web or API.
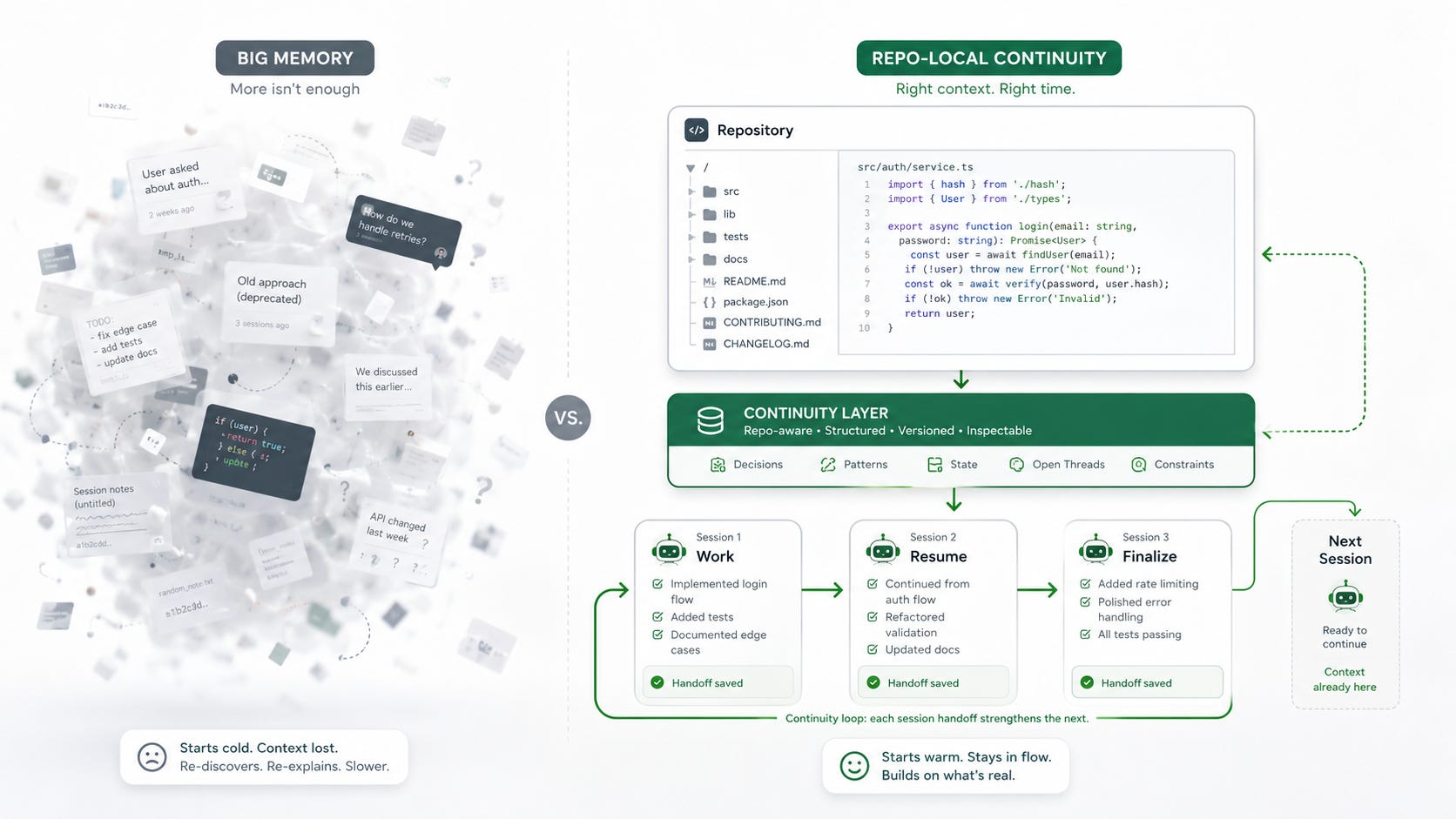
A practical reflection on why coding agents lose the thread between sessions, and why the repository itself is the right place to preserve it.

A native macOS app that monitors your home network. See every connected device, when it joined, and when something new appears — at a glance.

Nine banks have been offered access to GPT 5.5 Cyber, as fierce rival Anthropic has blocked previews of its tool.
Free browser-based developer toolkit: JSON validator, Code minifier, Code beautifier & formatter (JS/CSS/HTML/JSON/SQL/XML), Base64 encoder, Regex tester and more. Everything runs in your browser — no data sent to any server.