Channels
Like many people, I've been watching STRC struggle to hold its $100 level. I believe the mechanism intended to drive the price back to $100 has a design flaw that's causing it to fail to return to $100 target. There are two types of people in the STRC market — short term dividend arbitragers, and longer-term holders. The problem is that dividend arbitragers have been driving up supply of STRC to levels higher than the longer-term holders can consume. Each time an ex-dividend date occurs, dividend arbitragers buy STRC, hold it until the ex-dividend date, and sell it, with the aim of selling for price difference less than the amount they gain from collecting the dividend. They can do this with leverage using their broker's margin, and it has also been possible to double up on monthly dividends by also doing the same trade on SATA (another preferred stock much like STRC) as their ex-dividend dates are different. Unlike a normal stock, STRC issues new shares directly to buyers at the $100 level, so these dividend arbitragers are causing new shares to be issued in large numbers as they buy in. When they sell on the ex-dividend day, the extra share issuance becomes too much for longer-term buyers to absorb, so the price drives down. Because new shares are issued at $100, the price never goes over $100, and so there's no market mechanism to destroy demand from arbitragers — they can always buy at $100 as much as they like. In a normal stock, arbitragers would push up the price, making the arb unprofitable, but this doesn't occur in STRC. Many of these dividend arbitragers will be failing to sell at a profitable price, so they'll be trapped holding shares and trying to sell into buyers entering for the next ex-dividend date to get out of their losing trade. These trapped dividend arb traders make it even harder for the price to return to $100. The other problem is, Strategy's mechanism for pushing the market back to $100 is likely to make this worse. They can increase the dividend amount to incentivise buyers, but increasing the dividend may incentivise dividend arbitragers more than long-term buyers, as a larger dividend is more appealing and easier to arb, because of the larger spread between $100 and the sale price. The recent drop in BTC to ~$60k has likely hit sentiment amongst longer-term holders, leading to reduced demand to absorb the excess supply caused by dividend arbitragers triggering ATM issuance of shares. The current design has the effect of issuing more STRC than the market can bear. Increasing the yield may help temporarily, but as the price returns to $100, dividend arbers are likely to drive up supply again until the $100 level cannot be maintained. I think Strategy needs to: Change the issuance policy to not issue at $100, but at a higher level. This will make dividend arbing harder, as people will be buying high and selling low, making the arb less likely to be profitable. At the moment buyers can always buy at
Now that Binance didnt got its MICA license on time, its europeans users have to move to other exchanges before 1 July. Every exchange's name on the table has an hyperlink towards the authority of financial markets of France where you can check where and when they got the license. If you are not already on any of theses exchange I would suggest one of top 2, Kraken or coinbase. And if you move the funds, remember to convert everythng to one token (dont use USDT and chose one that is cheap on gas), test a very little transfer first( ALWAYS DO THIS FIRST) and then transfer evverything and then convert it to what you had but now on the new exchange. Rank Exchange MiCA statsu 1 Kraken Licensed MICA — entity: Payward Europe Solutions Limited / Kraken Digital Asset Exchange. Date: 25/06/2025. Licensing country: Ireland, authority: Central Bank of Ireland. 2 Coinbase Licensed MICA — entity: Coinbase Luxembourg S.A. Date: 20/06/2025. Licensing country: Luxembourg, authority: CSSF. S 3 Bitstamp Licensed MICA — entity: Bitstamp Europe S.A. Date: 15/05/2025. Licensing country: Luxembourg, authority: CSSF. 4 Bitvavo Licensed MICA — entity: Bitvavo B.V. Date: 14/07/2025. Licensing country: Netherlands, authority: AFM. 5 Bitpanda Licensed MICA — entity: Bitpanda GmbH. Date: 14/04/2025. Licensing country: Austria, authority: FMA. 6 OKX Europe Licensed MICA — entity: OKCoin Europe Limited. Date: 15/02/2025. Licensing country: Malta, authority: MFSA. 7 Crypto.com Licensed MICA — entity: Foris Dax MT Limited. Date: 12/02/2025. Licensing country: Malta, authority: MFSA. 8 Gemini Licensed MICA — entity: Gemini Intergalactic EU Ltd. Date: 21/08/2025. Licensing country: Malta, authority: MFSA. 9 Bybit EU Licensed MICA — entity: Bybit EU GmbH. Date: 28/05/2025. Licensing country: Austria, authority: FMA. 10 Gate EU Licensed MICA — entity: Gate Technology Limited. Date: 30/09/2025. Licensing country: Malta, authority: MFSA. The table was created by chagpt, I added the hyperlinks manually and centered it only in MICA. I have erased all traces of chatgpt from the hyperlinks. Good luck everyone submitted by /u/Wizard_of_the_lake [link] [Kommentare]
Hey guys, I was playing around with Nanotron recently and got super frustrated by how many heavy, hardware-specific dependencies it imports at the module level ( flash-attn , triton, functorch , etc.). If you try to run it on older or budget GPUs like a T4 or V100, it just crashes on import. So I wrote Picotron (https://github.com/Syntropy-AI-Labs/picotron) to solve this. It's a clean-room rewrite that gets rid of all mandatory GPU-specific dependencies. It runs on pretty much any GPU that supports PyTorch (defaults to FP16 on older cards under compute capability 8.0, and BF16 on newer ones). It falls back to standard PyTorch SDPA by default, but still hooks into FlashAttention-2 at runtime if it detects you have it installed. I used an AI assistant to write a lot of the boilerplate/code modules, but I've got it working locally and just trained a tiny 2M model on FineWeb-Edu. Also added configs for: • GQA / MLA (Multi-head Latent Attention) • QK-Norm & logit soft-capping (Gemma 2 style) • Parallel FFN/Attn runs • ZeRO-1 wrapping on DDP Roadmap is pretty short right now: MoE prep (routing capacity factors and load balancing loss) Making dataset prep easier than streaming manually Check it out if you've been fighting with CUDA dependency hell: https://github.com/Syntropy-AI-Labs/picotron submitted by /u/Capital_Savings_9942 [link] [Kommentare]
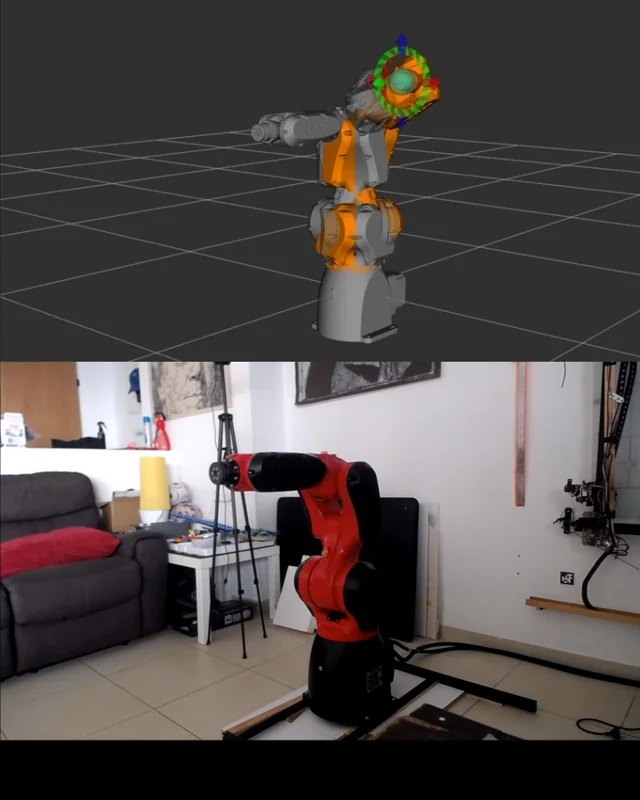
I have a Borunte BRTIRUS0707A 6-axis arm (HC1 controller, F5.2.1 firmware) and there was no ROS 2 support for it, so I created one and put it on GitHub: 👉 https://github.com/rqtqp/ros2_borunte_0707A It's a ROS 2 (Humble) workspace that talks to the controller over its JSON-over-TCP interface (port 9760) — no vendor SDK needed. What works today: Telemetry — live joint state on /joint_states, plus controller status/health. MoveIt 2 motion — Plan + Execute in RViz actually moves the real arm (the bridge turns the planned trajectory into the controller's AddRCC motion command). Safety — dry-run by default, live precondition gate (mode/alarm/limits), soft limits, and a /stop abort service. Model (URDF + meshes) and a MoveIt config included, plus a documented mechanical-zero (groove/blade) home calibration. Sharing it in case it's useful to anyone working with these arms. If you have questions about this piece of equipment (the arm, the HC1 controller, or its remote-command protocol), feel free to ask 🙂 submitted by /u/tru0ne [link] [Kommentare]
Hey everyone, I'd like to share my project along with a short explanation of the process and why it came about in the first place. To start off, I'm not exactly the best at cryptography/steganography, in my case it's always been something that sat in the background, as one of the sub-fields needed for another (main) field I'm actually interested in. For this project I tried to look up as much information as possible about what's currently considered best practice (I mainly relied on NIST for this), what implications exist, and what potential "attacks" exist against this way of hiding information, but I honestly can't say whether I covered everything, which is why I wanted to share this project here, mainly for the sake of learning. I'd be grateful for any feedback on what I could have done better / what I might have missed, etc. Right now, I consider this project closed at this point and will most likely not update it further, although I'd like to apply all the feedback to my own knowledge going forward. For over a month I did a lot of research into using ML models as a carrier for hiding data. I needed this as one of the stages for my main project. That's how I ended up on the topic of hiding information in model weights. Initially I assumed a simple method of directly writing data into randomly selected weights. I quickly concluded, though, that this would be absurdly trivial to detect, and potentially also to read. Next came the idea of using something like a deterministic coordinate map describing where to read the data from (location-id + position-id). The program wouldn't modify all the bits needed to write the message instead, it would write separate bits representing already-existing values (pointing to specific locations in the model) from which the existing 0s and 1s would need to be read. In practice, only parties A and B would know how to derive these positions. This way, someone unaware of the algorithm would only see what looks like noise of varying values. However, after a theoretical analysis of a practical implementation, this idea had serious flaws. Even setting aside the fact that the main goal was steganography and not encryption, the mere presence of additional data could be relatively easily detected, for instance through delta analysis against a reference model, or through analysis of the statistical properties of the weights. On top of that, this method would really only allow transmitting a very small amount of data, because just indicating, say, the word "example" would look like this: "01100101011110000110000101101101011100000110110001100101", so it would be extremely impractical. In other words, even if the hidden message itself couldn't be read, one could still suspect that the model contains hidden information, which would defeat the whole point of steganography. While I found the previous option conceptually pretty interesting, I moved on, which led me to the question: "How do I hide data in the weights in a way that won't be visible?" That led me to the next idea: since every fine-tuning process naturally changes some of a model's weights anyway, why not hide information only in the weights that get modified during training regardless? In that case, the fine-tuning itself would provide a natural and logical explanation for the presence of those changes, including when compared against a reference model. It was only later that I found out that similar/identical concepts had already been described in the scientific literature, although they remain a fairly niche research direction. Skipping over the implementation details (since everything is described in the README and SECURITY files, and I don't want to dump even bigger wall of text here), this is how the first implementation of the solution (part of my main project) came about. After further research I noticed that most existing publications focus on the academic side, while the available GitHub repositories were often poorly documented, limited in functionality, good steganographically but weak cryptographically, or were just a small piece of larger projects. Personally, I couldn't find any project implementing a similar idea specifically using models saved in the ONNX format. So I decided to split this part off and refine it as a separate proof of concept, and that's how ONNXStego came about. If anyone's interested in the security, limitations, or implementation details, feel free to check out the repository. I personally learned a great deal from this project and tried to describe the final conclusions/information I gathered while learning as precisely as possible, so I'm hoping the project can also be useful to others for their own purposes or projects. (If this counts as self-promotion, I apologize in advance, and I can remove this post for that reason too if needed, I tried to describe the whole process behind it as accurately as I could, to make the post as educationally useful as possible). Link: https://github.com/X-3306/ONNXStego submitted by /u/Admin-ABC-XYZ [link] [Kommentare]


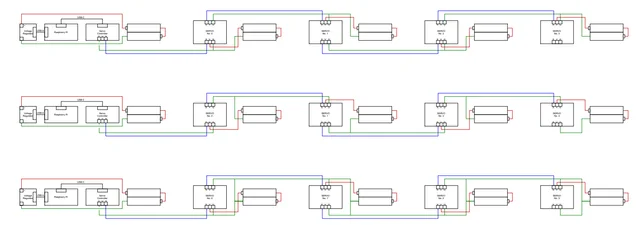
So basically I'm using: Feetech SCS-15 Serial Servo motors Feetech FE-URT-2 USB to TTL Controller Voltage Regulator Module (5V output) Raspberry Pi 3.7v 18650 Batteries to control the servo motors in the daisy chain ish way. For some reason I need to power servos using batteries individually, and I am not sure how I could do the wirings. Like, are they even different from one another and which way is the most adequate? In my poor understandings the ground seems all connected regardless of which way of these 3. submitted by /u/Dangerous_Break5656 [link] [Kommentare]

A few weeks back I posted about a little experiment: a cryptocurrency that runs entirely inside a browser tab called BrowserCoin. Open a page, you're a full node. Mining is memory hard so a phone and a server farm have about the same odds. Bitcoin shaped rules, fully open source, no market, just a project to have fun with the technology. A lot of people tried it out, and I would like to recap what happened so far, because it was pretty interesting. A very important thing about this project: it's not selling anything. The coin was made to have fun with the technology. There is no market, you can't buy coins, you can't sell them. Coins exist because someone mined them. That's it. This is what the tool looks like these days: Browser Coin Landing Page Okay. What's happened, roughly in order: A wave of you showed up. The first post sent a ton of people in. At peak times there were 600+ people mining. People started building. Mini games, a faucet, mining pools, little tools and toys I had nothing to do with. Watching strangers build on something was very cool to see. Community made Projects Someone fixed my biggest weakness. In a browser you can't connect to peers by raw IP, so you need a couple of helper servers to introduce new tabs to the network, and I was running the defaults, which made me a soft point of failure for joining. A community member wrote a way better system: helpers are now discovered automatically, anyone can run one, no approval from me. They're just bootstrap hints. Your browser still validates every block locally, so a helper can't forge anything or touch your coins. That was the last slightly centralized bit, and it wasn't even me who killed it. Advertise Helper Server Feature It became more decentralized and way less killable by attacking a single server. The whole chain now backs itself up to a public repo every hour, re-verifying everything from scratch each time. If every server and tab vanished overnight, anyone could bring the network back in about fifteen minutes. Every clone is another permanent, verifiable copy. Quality of life. Faster wallet loading, a better block explorer, and a pop-out miner, a little floating window with live hashrate and CPU sliders so you can keep mining while you do other stuff. All cool features that were developed while the chain was up and running. I burned ~195k BRC (those were mined when it was mostly just me testing the chain, so I thought it made sense to burn them) to a dead address. Gone forever, no key exists, tagged in the explorer. The address is 000000000000000000000000000000000000000000000000000000000000dead, which is kinda fun. Top holder with burn Wallet People are still out here mining, and the next big challenge is doing the first hard fork. The next step is adding scripts. BrowserCoin now has a scripting engine: lock coins behind a secret and a key, a raw-script mode, a full opcode reference, and lock/redeem transactions decoded and explained in the explorer. Same chain, your balance and history carry straight over. It activates automatically off the chain's own clock on July 5, so every updated tab flips at the same block, just refresh before then. Scripting Countdown Banner Once scripts are added there's a lot of other cool stuff to experiment with. A network of strangers who don't trust each other agreeing on a shared ledger with no one in charge, using nothing but math and electricity, and now a community building games and faucets on top of it. Still the most fun thing I've made. No nonsense. So far it was very fun. No one lost anything, no one gained anything but knowledge. An experiment to have fun with the technology the way it should be. submitted by /u/swompythesecond [link] [Kommentare]

