Channels
Hi everyone, I’m building an open-source machine-learning tutorial repository in Jupyter Notebook format: https://github.com/mohammadijoo/Machine_Learning_Tutorials The course is bilingual: English and Persian/Farsi versions are organized in parallel. The goal is to make a practical, notebook-first ML curriculum that students can run locally and study step by step. Current focus areas include: ML foundations and workflow data cleaning, preprocessing, feature engineering regression and classification tree models and ensembles clustering and dimensionality reduction evaluation, cross-validation, calibration time series, anomaly detection, responsible ML, and MLOps concepts datasets and exercises for hands-on practice I would appreciate feedback on: whether the chapter order makes sense for beginners what important classical ML topics are missing whether bilingual notebooks are useful for non-native English learners how to make the notebooks more practical without turning them into only “copy/paste code” I’m sharing this as a free educational resource and would value constructive criticism. submitted by /u/abolfazl1363 [link] [Kommentare]
I'm working on a paper and would love some input on model choice. Suppose you're trying to detect a specific type of cancer, but the negative samples are visually and morphologically very similar (i.e., “mimics” of the cancer). In this setting, would it make more sense to approach the problem as: Anomaly detection (treating the cancer as the target distribution and everything else as out-of-distribution), or Supervised classification (explicitly learning to distinguish cancer vs. mimics)? submitted by /u/DryHat3296 [link] [Kommentare]
Upfront disclosure: this is my write-up (and I'll link it below), but laying out the argument here so you can strawman/steelman it without clicking anything. Assertion 1: per token price is the wrong metric for measuring the cost of work done by LLMs/reasoning models. Users get charged the per token price regardless of whether the output/outcome was right or not. Assertion 2: real work lives in long chain processes. Reliability of agents (run through LLMs) drops geometrically in proportion to chain length. 95% per step accuracy translates to 77% process reliability for a 5-step process, 60% for 10, and under 36% for a 20 step process. This calculation holds if errors are independent, which isn't true for real world processes, ergo real world reliability is worse than that. This adds a verification tax on top of the price of tokens the user pays. You can verify through human intervention, inference time compute (less reliable than human intervention), or swallow the decay in reliability. Argument: granted 1 & 2, you can't reliably automate any meaningful work through LLMs/agents in a cost-effective way, because it isn't an issue of economics but of architecture (LLMs can't reason faithfully, which was my previous essay) Link: https://open.substack.com/pub/mauhaq/p/price-is-not-cost?r=7eoi8&utm_campaign=post-expanded-share&utm_medium=web submitted by /u/Sensitive_Air_5745 [link] [Kommentare]
Just thought I'd highlight this issue to the ML community, since I recently had this problem arise and it might be useful for some. I had a coauthor who I knew was somewhat untrustworthy when it came to LLM use. This coauthor added some last-minute new references to the paper. The deadline was near, and I had a ton of other stuff to take care of. I asked them to ensure the references were correct. This coauthor confirmed that all references were correct. I trusted them. I submitted the paper. Turns out, I made a critical mistake in trusting them. All of these newly added references had hallucinations in them. The reviewer pointed out the hallucinated references and we withdrew the paper. Besides this reviewer, we had all accept scores: the scientific content of our paper was strong. Of course, this damages my reputation and the reputations of the rest of the coauthors. The takeaway is: check *all* references added to the paper, unless you are absolutely certain you can trust someone to not use LLMs. Hopefully this helps someone avoid this issue, because I worked tirelessly on this paper, in a very high pressure lab environment, and this whole situation has caused me a lot of grief. submitted by /u/treeman0469 [link] [Kommentare]
Hi, About a year ago I shared my PaddleOCR implementation here. Since then I've made many improvements, and it now supports PP-OCR v3 through the latest v6 models. The official Paddle C++ runtime has a lot of dependencies and is very complex to deploy. To keep things simple I use ncnn for inference, it's much lighter (and faster in my task), makes deployment easy. Hope it's helpful to some of you, and feedback welcome! https://github.com/Avafly/PaddleOCR-ncnn-CPP submitted by /u/Knok0932 [link] [Kommentare]

A direct optimization test was conducted on a neural network for MNIST image classification. The network features a 784-32-10 architecture with a total of 25,450 continuous parameters (weights and biases). Instead of employing backpropagation or gradient information, the parameters were optimized using MDP, a Derivative-Free Optimization method. The objective was to directly minimize the Cross-Entropy Loss on a subset of 5,000 training images. Final evaluations were performed on independent validation and test sets. In the best run, MDP achieved an objective loss of 0.0004083, a validation accuracy of 93.7%, and a test accuracy of 93.4%. These results outperform the baseline established by Adam, which achieved a final loss of 0.002945, a validation accuracy of 91.8%, and a test accuracy of 91.7% using the same network architecture. Notably, this optimization was successfully performed over a 25,450-dimensional search space, achieving convergence across 1,000,000 function evaluations without relying on gradients or population-based methods. The code for this test, along with other Python implementation examples, is available in the examples folder of the official project repository: https://github.com/misa-hdez/sgo-lab submitted by /u/Mis4318 [link] [Kommentare]
my preprint is on SSRN and i feel somewhat shy to share it here... but the PKU lab's paper that cited mine got accepted by ICML 2026: https://arxiv.org/html/2602.06358v2 submitted by /u/max6296 [link] [Kommentare]
Can anyone please guide me on how to prepare for Amazon ML Summer School? I’m quite confused about where to start and what topics are most important for the selection process. Any tips, resources, or preparation roadmap would be really helpful. Thanks! submitted by /u/addiemaddieee [link] [Kommentare]
Hi all, A real story from my current experience: I'm associated with an internship where the primary work revolves around autonomous UAVs. What has shocked me the most is that almost everyone is so heavily focused on coding agents and AI tools that they're building things without paying enough attention to the fundamentals. This got me thinking: what if we conduct a virtual session on the fundamentals of Computer Vision? This idea comes from my own experience as well. During my first semester, I was terrified of learning from documentation and kept chasing YouTube tutorials instead. Later, I realized that some of the most interesting and valuable concepts are actually explained in the documentation itself. What do you all think about conducting something like this? How many of you would be interested in joining a one-day session? submitted by /u/FishermanResident349 [link] [Kommentare]
Hey everyone, I am planning out a new open-source infrastructure project and want to get some brutal feedback on the architecture and use-case validity from people running high volume LLM workloads in production. The Problem: Python-based proxies/gateways introduce too much latency overhead for real-time streaming agent steps or fast UI completions. Additionally, centralized semantic caching still suffers from cross-region network latency (e.g., London to us-east-1), and enterprise API costs remain a massive bottleneck for repetitive/predictable user queries (like customer support or structured data extraction). The Proposed Architecture: Instead of a heavy centralized gateway, the goal is to build a lightweight, zero-dependency semantic cache running directly at the CDN Edge using WebAssembly (WASM) compiled from Rust. The flow looks like this: Inbound Prompt: Hits the edge node closest to the user (e.g., Cloudflare Workers / Fastly Compute). Edge Embedding: The Rust/WASM module intercepts the raw text prompt and instantly generates a vector using an edge-native lightweight model (e.g., bge-small-en-v1.5). Similarity Index Check: It performs a fast cosine similarity check against an edge vector database (like Cloudflare Vectorize) to find the nearest semantic neighbor. Cache Hit: If similarity >= threshold (e.g., 0.88), it pulls the full generated response text from an edge KV store and returns it in ~5ms. The main LLM provider is never billed or touched. Cache Miss: It proxies the streaming request to OpenAI/Anthropic/vLLM, streams it back to the client, and asynchronously updates the edge vector index and KV store. Why Rust/WASM? To achieve sub-millisecond execution overhead on the proxy itself, avoid garbage collection pauses, and maintain a tiny memory footprint suitable for edge runtime constraints where traditional databases or Python scripts cannot run. My Questions for the Community: For those running LLMs in production (especially customer support, internal RAG, or autonomous agents), what is your realistic semantic cache hit rate? Is the power law of repetitive queries high enough in your domains to justify this? What are the biggest footguns with semantic caching at the edge? (e.g., Cache invalidation strategies, handling system prompt updates, or drift in embedding models). Would you actually use a drop-in open-source template/CLI that lets you spin this up on your own edge account, or do you prefer centralized API gateways? submitted by /u/Real-Huckleberry-934 [link] [Kommentare]
I've written a C++ implementation of distilHuBERT. https://github.com/pfeatherstone/hubert.cpp It has no runtime dependencies, the weights are compiled into the library, it supports dynamic sizes, has performance on par with onnxruntime (in my tests) and can be easily integrated into any CMake project. Please let me know your thoughts. submitted by /u/Competitive_Act5981 [link] [Kommentare]
Results are almost here. Good luck to everyone waiting for the final decision 🙂 submitted by /u/Sea_Muscle_4281 [link] [Kommentare]

https://preview.redd.it/wsq4fyhpzr6h1.png?width=745&format=png&auto=webp&s=7ade94f5852667bf6a820398e3fcf8dcb0d450af submitted by /u/HitarthSurana [link] [Kommentare]
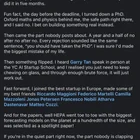
“…5 papers at ICML (1 Spotlight)…” “…Five ICML papers is what a strong PhD produces in four years. I did it in five months…” I recently saw these posts from people at the same AI company. At first, I was extremely surprised. It turned out they were workshop papers. Am I missing something here, or are workshop papers now being treated as equivalent to main-track papers? submitted by /u/Terrible-Chicken-426 [link] [Kommentare]
Are there any websites listing post-doc job opening in machine learning? Currently I'm using LInkedIn to search for these. When I was a math post-doc, everyone used "MathJobs.org" to find jobs. Is there a similar website for machine learning? Thanks. submitted by /u/random_sydneysider [link] [Kommentare]