Channels

I was trying to pay for something using bitcoin, and every now and again (more often on the first copy attempt) it would copy a completely different address? I didn't double check the address upon checkout, and the seller says that address has nothing to do with them. Clarification: When copy+pasting this address, whether you use the button, or do it manually, sometimes throws out a completely different address that's (according to him) has nothing to do with the seller. submitted by /u/Fluffy-Suit-3650 [link] [Kommentare]
Hello, I’m a 19-year-old student who recently graduated from high school and will be starting college this September. I’ve been thinking about creating affordable robotics kits and courses for children. I want to offer “build your own” projects, such as small cars, robotic arms, and other fun electronics projects. My idea is to create three levels: Beginner, Intermediate, and Advanced, so that kids of all ages and skill levels can learn and challenge themselves. My goal is to make these kits and classes as affordable as possible. In the beginning, I’m not focused on making a profit. When I was younger, I never had the opportunity to learn robotics on my own and was lucky to receive help from others. I’ve also realized that many robotics classes are very expensive, and I want to make this kind of education accessible to more children. I’d love to hear your thoughts. Do you think this is a good idea? Are there any challenges I should be aware of? Thank you very much! submitted by /u/Mf_KingIsHere [link] [Kommentare]
(this was deleted before but i dont know if it was the filters of reddit or the moderators, if is the moderators i will not post it again after you delete it sorry.) (The name will probably change soon because I didn't realize "AgroVision" is already a registered trademark lol.) Link: https://agrovision10.vercel.app/ AgroVision DEMO is a personal project that started as a university assignment. It attempts to propose a solution to a real problem in Nicaragua: crop loss caused by misinformation or difficulty accessing useful agricultural information. The traditional methods Nicaraguan farmers use are gradually becoming less accurate due to global warming, and the rise of artificial intelligence opens up new and interesting possibilities. What is it? AgroVision is a free demo that aims to help small and medium-scale producers in Nicaragua decide what crop to plant, when, and with which inputs — by simulating the future climate of their area and calculating whether it's worth it or not, in real córdobas. In general terms, AgroVision is an expert system that lets you "simulate" having a farm. You have your supplies, your available crops to plant, and your plots with their respective active or passive tools. A passive tool would be a specific mesh netting, and an active one would be an irrigation system that activates when needed. You also define your plot's soil type, terrain slope, the year you want to plant, and the specific municipality — we have all of them in Nicaragua. The system has information on each available crop: its growth phases, when planting begins in Nicaragua's 3 main agricultural cycles (primera, postrera, apante), when each cycle ends, water requirements in mm per phase, and most importantly, what climate conditions are ideal for that crop. With this, the system knows what climate conditions to expect for each future day in your area. With all that information, the system simulates what would happen if you planted a certain crop on that plot: which losses are unavoidable due to climate, which are avoidable if you have certain tools or supplies, and finally gives you the result in money generated, quintals produced, and much more. You can even change the sale price per quintal if you want to explore hypothetical scenarios. How did we build it? First comes the NASA data. Using machine learning — essentially specialized math applied to computers to find patterns in phenomena — I obtained daily climate data in 50×50 kilometer grids covering every part of Nicaragua. Being 50×50 km grids, the information is moderately precise. For comparison: weather apps on your phone typically use 20×20 km grids for rainfall, which allows them to predict rain hours in advance. AgroVision's data is more general for now, which works fine for some variables but could improve for others like rainfall, depending on data and resources we obtain in the future. That said, we do provide more precise solutions for variables that require it, like soil moisture at the root level. The variables obtained from NASA are: PRECTOTCORR: Rainfall (mm per day) T2M_MAX / T2M_MIN / T2M: Maximum, Minimum and Average Temperature (°C) WS2M: Wind speed (m/s) RH2M: Relative Humidity (%) ALLSKY_SFC_PAR_TOT: Photosynthetically Active Radiation (W/m²) ALLSKY_SFC_SW_DIFF: Diffuse Radiation (W/m²) GWETTOP / GWETROOT / GWETPROF: Surface, Root Zone and Deep Soil Moisture (fraction 0 to 1) T2MDEW: Dew Point (°C) TS: Soil Temperature (°C) BRECHA_ROCIO: Dew Gap, calculated as T2M_MIN minus T2MDEW (°C) This data was collected daily from 2010 to 2025. Then, using machine learning, I trained a model that learns the mathematical patterns of each variable and uses them to predict future years. We now have these variables projected for 2026–2029. In Nicaragua these variables are especially erratic, which makes this problem particularly interesting. In the graphics section of the site you can see how those predictions turn out. The model successfully captures general patterns, but extreme events like very strong storms or specific natural phenomena can't be detected realistically with this approach — that requires different data, engineering, and resources. The government already handles this with specialized techniques and a different approach, focused on informing days or weeks in advance. The pillars of the simulation engine Even though I'm not an agronomist, the system is built on real scientific principles: 1. Yield Gap Analysis The plant starts with the potential to produce 100% of its harvest. The system assumes that maximum from the start and subtracts percentages when climate causes losses that couldn't be countered. It's more realistic for predicting damage than trying to "add up" growth day by day. 2. Stateful Bucket Model The soil works like a sponge with two layers: the surface, which fills quickly with rain but evaporates fast, and the root zone, which fills more slowly but retains water longer. If it poured on Tuesday, the sponge is full. If Thursday and Friday are sunny with no rain, the system doesn't cry "drought!" — it checks its virtual sponge and says "relax, the roots still have water from Tuesday." This replaces generic NASA data with a plot-specific microclimate for variables that directly affect the plant. 3. Phenological Thresholds Climate doesn't affect a newly germinated plant the same way it affects one in flowering. The engine evaluates each climate event according to the exact growth phase of the crop. 4. Strict Climate Synergy Pests and fungi don't appear out of nowhere — they need the exact combination of conditions. For example: "If humidity is >85% AND temperature is

I'm planning to make a micromouse for a competition. I'm gonna use two 6v 500rpm n20 motors for the project. The weight of the robot will be around 200g. What will be the maximum speed that can reach? How will the acceleration be? Is the motor a good choice? submitted by /u/Turbulent-Dust-1590 [link] [Kommentare]

Top voted comment every day will form a new coin mutation into this guy’s body until he becomes indistinguishable, basically. Just a l’il something to keep things fresh during the final innings of the bear. Enjoy! submitted by /u/GrannyRocketeer [link] [Kommentare]

[Project] Post-hoc Adaptive MoE Gating on Qwen3.6-35B — empirical benchmarking of an open research gap Adaptive MoE routing — selecting a variable number of experts per token based on routing confidence — has been studied in papers (XMoE 2024, DynMoE ICLR 2025, TopP routing Huang et al. 2024). All successful implementations train from scratch. Nobody has published empirical results for post-hoc application to a pretrained fixed-k model at production scale. This is that experiment. What we built An inference-time patch to llama.cpp for Qwen3.6-35B-A3B (256 experts/layer, k=8 fixed) that applies cumulative probability thresholding to expert routing weights after normalisation. The GGML static graph constraint prevents truly dynamic k — the workaround is zero-gating: all k FFNs compute, but low-confidence experts are zeroed and renormalised out of the output. Threshold, min_k, and max_k cap are runtime-configurable via env vars. Results (PPL on PTB, 192 chunks, ctx=512) Config PPL ±σ Avg experts active k8 baseline 11.3277 ±0.143 8.00/8 k8 + threshold 0.75 12.1226 ±0.155 5.42/8 k12 no gating 11.3379 ±0.144 12.00/12 k12 + threshold 0.90 11.2925 ±0.143 10.31/12 Key empirical finding Post-hoc threshold gating on a fixed-k trained model cannot produce meaningful per-token variability without quality cost. The router's distributions after norm_w are flat by construction — training with fixed k=8 produces distributions like [0.16, 0.14, 0.13, 0.12, 0.12, 0.11, 0.11, 0.11]. The threshold has nothing peaked to bite into. Cutting from 8 to 5.4 experts removes experts contributing 11-13% of the output each — that's real signal loss, not noise. The k12 + 0.90 result (PPL 11.2925, marginally below baseline) is interesting precisely because it uses 4 experts the model was never trained to use. AMG at 0.90 removes the weakest 1-2 of those untrained extras, leaving a slightly cleaner signal. Whether this is a real effect or noise is ambiguous at ±0.143 error, but the direction is consistent. What's genuinely new No published work describes a working ggml_map_custom1 callback for adaptive gating in a production inference engine. The zero-gating workaround for static GGML graphs is a practical contribution. The empirical quantification of why post-hoc AMG is limited on fixed-k models fills a gap the papers don't address — they all train from scratch and don't measure the degradation curve of applying adaptive gating to a pre-existing flat-distribution router. Open problem The path to genuine per-token variability is router fine-tuning with entropy regularization (L = L_LM + λ_entropy H(router) + λ_balance KL(usage, uniform)), targeting only the 21M gate weight parameters with all expert FFN weights frozen. A training pipeline for this is included. Hardware requirement is ~20GB VRAM — currently blocked on 16GB A5000. If anyone wants to run it, the script is ready and I'd be interested in the results. GitHub: https://github.com/cjhudlin/Adaptive-MoE-Gate-AMG-for-Qwen3.6-35B Full methodology, raw perplexity logs, patch script, and router training pipeline included. submitted by /u/cjhudlin [link] [Kommentare]
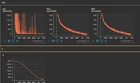
Hello, I'm trying to implement the Pocket TTS by kyutai-labs represented by this paper. Since they have didn't released the training/fine-tuning code. I'm trying to implement it on my own for learning some stuff. I have read the paper, tried to implement it with much more smaller parameters with smaller amount of data. I implemented this text to speech with one speaker on LJSpeech (1) and LibriSpeech clean subset but its hardly failing. For (1), Since it's a single speaker dataset I didn't added the voice cloning just simple text and target latents. flow matching loss became nearly 0.20 mse , EOS loss became very low like (x)e-(y) levels. But when infer with the model saved at 2800th epoch, It barily generating a meaningfull text even the text within its training set. Tried different techniques like Scheduled sampling for eliminate exposure bias (model was hallucinating sometimes and repeats same phrases twice), it didn't worked. Added std gaussian noise to ground truths, didn't worked. After struggling with lots of implementation I decided to move forward with quite larger dataset LibriSpeech because I thought that scale of the data was small. For (2), I read the paper again. No scheduled sampling, added the head multiplication etc, and implemented the paper in the librispeech dataset. I tried audio condition+ text tokens + BOS + target latents, and swapped the audio prompt with text tokens. I observed a tradeoff in this setup: if I put text tokens near to target latents, model generates better text but voice is not even close to audio prompt,and gibberish speak with better voice cloning when I put audio condition tokens near to target latents. And found out that loss is very spiky, and grad norm is exploding too you can see below the images. loss and lr values for setup 1 (LJSpeech) values for setup 2 (LibriSpeech) I used Pocket TTS' orijinal Mimi Audio Encoder by extracting it from Original model. What is your suggestions? Should I read paper over and over again? Should I increase the data amount by collecting from different sources(authors says that they used 88.000 hours of publicly available data)? Any system design problem? Trainings performed on RTX 5080 desktop gpu. I want to move on to bigger dataset but can't burn GPU credits for non-expected result. When should I increase dataset and start training on bigger clusters that could give me satisfyable results? submitted by /u/No-Motor-6274 [link] [Kommentare]



