

Hi, Niels here from the open-source team at Hugging Face. At paperswithcode.co I am trying to make it easier for people to learn about the newest techniques used across AI papers. One of the hottest terms in AI research that I've recently added is On-policy distillation, also abbreviated as OPD. It's the key post-training behind models like Qwen 3.6 and 3.7, GLM-5.1, and DeepSeek-V4. https://preview.redd.it/yegq2gfag95h1.png?width=3046&format=png&auto=webp&s=f68fdf3ca075f3c4e56051fdd0ebcf97be9bcbc9 On PapersWithCode, you can find the original paper that introduced it, learn more about the method itself, as well as all papers that cite or mention it. Sasha Rush (who used to be a colleague of mine at Hugging Face, now at Cursor) recently made an excellent whiteboard explanation of OPD with Dwarkesh. I've linked this video lecture in the method description on PwC's website, so more people can find it. I'll copy the excellent short description of the method from Dwarkesh here: "The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory. So we have another model to read this trajectory and figure out where the error was made. It simply inserts some hint tokens into the part of the trajectory immediately above where the mistake occurred. Now, with these injected hint tokens, run a forward pass through the model. You're not having to regenerate a new rollout - aka no new decode required. The hint causes the model to assign lower probabilities to the error tokens. You then train the original model to match these new probabilities, teaching it to downweight that specific mistake." Let me know which other methods I should add! Cheers submitted by /u/NielsRogge [link] [Kommentare]
The Google paper on metacognition for hallucination reduction makes a distinction that is underappreciated in benchmarks. Calibration is not about being right more often. It is about matching confidence to correctness. A perfectly calibrated model can still be wrong twenty five percent of the time. It just does not pretend otherwise. In agent systems this distinction matters more than in chat. A conversational model giving a hedged answer is slightly annoying. An agent with tool access acting confidently on a wrong premise is dangerous. I have been trying this in a small verdent based coding setup by splitting the pipeline into a planning stage that produces a task graph, then running a verifier before any expensive tool gets invoked. The risk is the model trusts its own reasoning even when speculative. Grounding helps but it is not the same as calibration. One practical pattern: a planning stage produces a task graph, then a lightweight verifier checks whether the plan is consistent with available evidence. This catches about sixty percent of hallucinated tool calls in my setup before they execute. The downside is the utility tax. Extra verification adds latency. Dropping hallucination from twenty five to five percent costs about half the easy correct answers, mirroring the paper. My current compromise: let the planning layer flag low confidence tasks for human review, but auto execute high confidence ones. The reviewer only sees edge cases instead of drowning in every step. The awkward part is that most agent stacks still treat confidence as a log detail, not as a control surface. submitted by /u/Ill_Awareness6706 [link] [Kommentare]
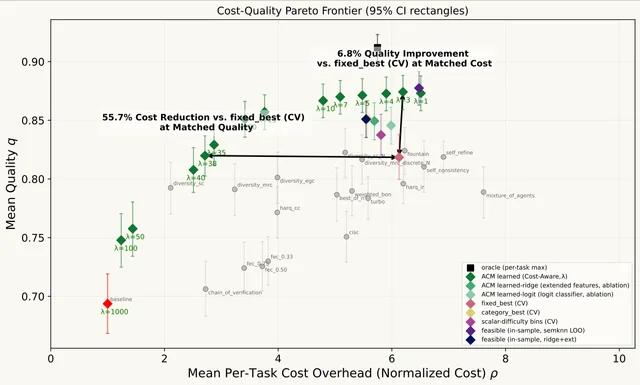
TL;DR: Reliability techniques (methods that boost an LLM's correctness by spending extra inference, e.g., retries with feedback, ensembling, generator/critic refinement, verification passes, difficulty-aware routing) are scattered across the literature, each in its own paper-specific codebase. We unified 28 reliability techniques (21 communication-theoretic methods across 6 families plus 7 prior-method baselines: Self-Consistency, Self-Refine, CoVe, BoN, Weighted BoN, CISC, MoA), each measured against an uncoded single-pass baseline, under a single API, with 3 adaptive routers (SemKNN + two local ACM routers) sitting on top, then showed that routing the technique adaptively per prompt lets you slide along a quality/cost frontier. In our paper benchmark with one specific lineup, Nemotron + Devstral as the two generators and GLM-5.1 as the judge, the adaptive router delivered ~56% cost reduction at matched quality, or ~7% quality bump at matched cost, vs the best fixed method we compared against at that same lineup. One knob (λ) does the sliding. The qualitative pattern (adaptive beats fixed) should generalize, but absolute numbers are lineup-specific, and we haven't run the full sweep across other model combinations yet. Adoption is change one import: python - from openai import OpenAI + from agentcodec.openai import OpenAI Pass reliability="harq_ir" (or any of the 28 techniques) and existing client.chat.completions.create(...) calls keep their native OpenAI response shape. Same drop-in shims for Anthropic and Ollama. GitHub: https://github.com/intellerce/agentcodec Working paper: https://arxiv.org/abs/2605.09121 After spending a while researching reliability methods from papers, we kept hitting the same wall: every paper ships its own one-off codebase with its own prompt format, its own scoring rubric, its own model wrapper. Benchmarking "should we use self-refine or best-of-N here?" turned into a week of plumbing per comparison. The communication-theory framing is what tied it together: an LLM is a stochastic channel Y = A(X) + N, and every reliability technique from the wireless world has a direct analog in agent-land: Wireless Agent-land ARQ / HARQ retry-with-feedback loops Diversity combining (MRC/SC/EGC) ensemble multiple models Turbo decoding iterative generator/critic mutual refinement Fountain codes rateless sampling, stop when the judge is confident FEC answer + structured parity passes (re-derivation, verification, alternative), decode by cross-check ACM (adaptive coding-modulation) route by difficulty We put all of them in one library: 28 reliability techniques (the 7 prior-method baselines are part of that 28, not on top of it), plus the uncoded single-pass baseline they're all measured against, plus 3 adaptive routers (SemKNN + two local ACM routers) that select a technique per prompt. Full breakdown in the README. The minimal version ```python from agentcodec import ReliabilityModule mod = ReliabilityModule.from_dict({ "models": [ # Spatial diversity: two different families = uncorrelated errors {"model": "qwen3:8b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, {"model": "llama3.1:8b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, ], "judge": {"model": "gemma3:12b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, "critic": {"same": True}, "strategy": {"type": "fixed", "technique": "harq_ir", "params": {"max_rounds": 4}}, }) result = mod.run("Prove the sum of the first n odd integers is n2.", category="reasoning") print(result.text, result.cost_usd, result.cost_source, result.technique_used) ``` Swap "harq_ir" for "diversity_mrc", "turbo", "fountain", etc. Same API, same ReliabilityResult shape, same cost-source tier on every output. For production, flip strategy to routed and the library picks the technique per prompt (cheap baseline on easy prompts, diversity_mrc on hard ones). Three things worth calling out Beyond the technique catalog, three pieces of the implementation that took real work: 1. Native async streaming for all but 2 techniques (acm_soft, acm_learned), with role-tagged events. mod.astream() drives AsyncOpenAI / AsyncAnthropic / httpx.AsyncClient end-to-end (no worker-thread bridge) and emits TokenEvents tagged with a role: "answer", "thinking", "draft", "critique", "verification", "candidate", "synthesis". So when you stream a HARQ-IR run, you can render the round-by-round drafts and critiques live, not just the final answer: python async for ev in mod.astream("Explain QUIC vs TCP."): if isinstance(ev, TokenEvent): if ev.role == "answer": print(ev.text, end="", flush=True) elif ev.role == "draft": print(f"\n[draft] {ev.text}") elif ev.role == "critique": print(f"\n[CRITIC] {ev.text}") elif ev.role == "thinking": pass # captured to result.thinking_text elif isinstance(ev, FinalEvent): print(f"\ndone — {ev.result.technique_used}, " f"thinking_cost=${ev.result.thinking_cost_usd:.4f}") Parallel-branch techniques fan out concurrently via asyncio.gather. diversity_mrc with two models actually runs them in parallel, and you see per-branch ProgressEvents as each one completes. 2. Thinking-text capture across all backends. Anthropic ThinkingBlock, OpenAI reasoning_content (+ exact reasoning_tokens from usage.completion_tokens_details), Ollama msg.thinking, and inline ... tag stripping (DeepSeek-R1, Qwen3, GLM-4.5+, Nemotron) all populate result.thinking_text and split result.cost_usd into thinking_cost_usd + answer_cost_usd. So you can finally see what the o-series / Claude / DeepSeek is actually charging you for. 3. Drop-in compat shims with expose_reliability_stream=True. Default: the shim looks identical to the native SDK, delta.content for the answer, delta.reasoning_content for thinking. Drafts/critiques are hidden so existing code keeps working unchanged. Set the flag and the shim surfaces internal roles via sentinel fields (delta.agentcodec_role, delta.agentcodec_call_id) that existing consumers ignore harmlessly: ```python from agentcodec.openai import AsyncOpenAI client = AsyncOpenAI(api_key=KEY, reliability="harq_ir", expose_reliability_stream=True) Now drafts/critiques flow through the native OpenAI stream with sentinels. ``` Same flag and same semantics on agentcodec.anthropic.AsyncAnthropic and agentcodec.ollama.AsyncClient. Other useful bits Cost transparency built in: every result carries a cost_source tier marking how the price was obtained, from exact_user_rate (you supplied the rate) through openrouter_rate / exact_table_rate / inferred_table_rate down to default_fallback, plus token-estimation flags when only character counts were available. Live pricing fetched from OpenRouter, cached locally for 7 days. No more "I think this run cost $40, maybe?" Works against whatever you have: OpenAI, Anthropic (native SDK), Ollama (native + python lib + OpenAI-compat), vLLM, OpenRouter, LM Studio, Together. No Docker, no separate inference server, no LangChain. Strict config schema: typos in YAML / dict configs raise at load time, not on first .run(). 195 tests, 25 runnable examples under examples/: async streaming, thinking capture, drop-in compat for all three backends, plus a fully-annotated YAML config. Caveats The headline numbers are for a specific model lineup. The ~56% cost / ~7% quality figures come from a single benchmark run with Nemotron + Devstral as the two generators and GLM-5.1 as the judge. We expect the qualitative pattern (adaptive routing dominates fixed) to hold for other model combinations, since that's the whole point of the framework, but the absolute numbers will move with the lineup, and we haven't done the cross-lineup sweep yet. If you swap in different generators expect different absolute savings; the right comparison is your adaptive vs your best fixed baseline at your lineup. License is PolyForm Noncommercial 1.0.0: free for research, teaching, personal/internal eval. Commercial use needs a separate license. The trained SemKNN routing artifacts (learned router mapping prompt embeddings → best technique, the thing that delivers the headline cost number) are not redistributed; the client talks to a remote SemKNN service. All other routers (fixed, acm_table, acm_linear) run fully locally, though the last one needs you to train it. 2 techniques (acm_soft, acm_learned) still fall back to sync dispatch in an executor on the async streaming path. They produce correct FinalEvents but no mid-stream tokens. Roadmap. This is research code. Expect rough edges on the less-traveled paths (soft-output diversity variants, the learned ACM router). Feel free to ask about specific techniques, the routing approach, how to add a new one, or the streaming / thinking / compat work. Suggestions on what to ship next are welcome. submitted by /u/Intellerce [link] [Kommentare]
As an ML researcher, how do you use AI tools in your daily work? Do you mostly use them to clean up grammar and wording, or also to rewrite, structure, or draft technical text? submitted by /u/Hope999991 [link] [Kommentare]

The prediction that equivariance reduces sample complexity by a factor of |G| appears in roughly every paper on geometric deep learning and is measured as an actual scaling law in roughly none of them. This paper does the measurement. The methodology is the interesting part. Naive estimators conflate group order with task difficulty (larger groups induce harder symmetry structure, not just more constraint), so the authors derive a relative exchange rate that cancels the shared difficulty out, meaning roughly how much less data the equivariant model needs compared to a vanilla baseline as a function of n, on a controlled C_n-symmetric task where n is a free knob. They also pre-specify a failure taxonomy: explicit conditions that would count as evidence against the hypothesis before seeing results. The headline number is beta_diff ~ 1.28, consistent with the theoretical 1.0. But the more durable finding is the wrong-group control: a model built with the wrong cyclic symmetry, same orbit size and same compute budget, is actively worse than no constraint. Not noise. The joint pairwise CI [+0.79, +3.26] excludes zero robustly across every estimator they run. Misalignment isn't just unhelpful; it is harmful. There is also a clean mathematical result slipped into Sec. 4.3: augmentation + test-time orbit averaging is exactly equivariant for output-pooling architectures, provably and verified to bit-identical training curves. The architecture-vs-augmentation gap collapses to whether you apply the orbit average at test time, not to anything structural. This seems underappreciated. The paper is unusually transparent about what it didn't nail: the relative-rate estimator was adopted post-hoc, the two-level bootstrap CI (seeds x group sizes) includes zero, and a finer-N replication on a sqrt(2)-spaced grid is inconclusive. They rank their findings explicitly by robustness. The wrong-group result is the one they would stake a claim on. The exchange rate is directionally probable. submitted by /u/AhmedMostafa16 [link] [Kommentare]
Hello everyone, Is it allowed to use OpenAI API outputs to create a silver code dataset or benchmark for a specific Python library? I am working on a project idea related to library-specific code generation. The concrete case is a specific Python library used in a technical/scientific domain. The goal would be to improve and evaluate how well code-generation models can use this library correctly. I am trying to understand the legal / Terms of Service boundary around using OpenAI API outputs in two different scenarios: Scenario 1: Silver dataset for fine-tuning an OSS model Use the OpenAI API to generate programming tasks, reference solutions, and verification tests for the specific Python library. Then human-review, filter, and validate the generated examples. Then use this silver dataset to fine-tune an open-source code model, with the goal of improving its performance on this specific library. My question: would this violate OpenAI’s terms because the API outputs are being used to train/fine-tune another coding model, even if the scope is narrow and library-specific? Scenario 2: Benchmark only, not training Use the OpenAI API to generate programming tasks, reference solutions, and verification tests. Human-review and validate them. Then use the resulting dataset only as an evaluation benchmark to compare different models. The benchmark would not be used to fine-tune or train any model. My question: is this generally considered allowed under OpenAI’s terms, assuming the benchmark is properly reviewed and documented as AI-assisted? I understand that Reddit is not legal advice, and I would still contact OpenAI or legal counsel for a definitive answer. However, I thought new ideas could come up from people who have already faced similar situations in practice. submitted by /u/ororo88 [link] [Kommentare]
It seems raw teleoperation data (RGB + joint states) structurally lacks affordance, contact intent, and embodiment-specific kinematic context. (information that can't be reliably recovered post-hoc once the demonstration is recorded) Most current approaches either filter/clean after collection, or rely on simulation to compensate. But neither seems to close the semantic gap for contact-rich tasks in unstructured environments. Is anyone working on supervision at acquisition time, enriching the stream as it's captured rather than labeling after the fact? And if not, is this a real bottleneck or am I overestimating the problem? submitted by /u/Several-Many9101 [link] [Kommentare]
About 10 years ago, I got into the basics of ML (like regression, KNN's, LVQ's) and read a few papers before taking a break a few years back. It feels like now, there's a lot of researchers in AI. How do you identify the ones who are actually solid vs those who (forgive my phrasing) are more researchers for appearance/status (i.e don't actually know what they're talking about)? Is the core filter h-index or where they work? How would you identify them? submitted by /u/roguejedi1 [link] [Kommentare]
I have a paper accepted at a non-archival ICML workshop this year, and I am trying to decide whether it is worth registering and attending. By coincidence, I will already be in Seoul around that time, but I would have to pay the workshop registration fee (~$400) out of my own pocket. I would only be registering for the workshop day since I have other commitments during the rest of the conference. I am thinking of applying to PhD programs this fall (I applied this year too, but didn't get in), and the workshop speakers and panellists look genuinely great. Not sure what the real benefits are here or whether I should go for it. For context, I am also attending ACL 2026 this year, but that trip is fortunately sponsored, so this would be a separate personal expense. I would also appreciate guidance on how non-archival workshops work in general. Since the paper is non-archival and not formally published (at least to my understanding), is registration still expected or required for accepted papers? Do authors typically attend and present in person, or is it common to skip attendance and conference registration? Has anyone been in a similar situation? I want to understand the benefits of this. Any advice would be greatly appreciated because I honestly have no idea how to evaluate this. submitted by /u/YOYOBOYOO [link] [Kommentare]
Most explanations of TPUs and systolic arrays are either hand-wavy diagrams or papers. I wanted to see the thing actually run, so I built it. TinyTPU is a 4×4 weight-stationary systolic array in real SystemVerilog, compiled to WebAssembly, with a step-by-step browser visualization. You enter two matrices, hit run, and watch the actual hardware execute: weights loading into PEs, matrix A streaming in diagonally (the "skew" that makes systolic arrays work), partial sums accumulating down the grid, results draining from the bottom. It has three levels: L1 - isolate a single MAC cell, watch one multiply-accumulate happen L2 - the full 4×4 array executing a real matmul L3 - tiling: what happens when your matrix is bigger than the hardware Nothing on screen is faked. The visualization reads state directly from compiled RTL. If you're trying to understand how matrix multiply maps to hardware why TPUs are efficient, what "weight-stationary" actually means, why the diagonal stagger exists this might click it for you in a way papers don't. Repo: tiny-tpu Live demo: Live If this project interests you please do star the repo, if you find something needs improving open a PR, I hope ya'll check this out and give me some feedback 🙏 submitted by /u/Horror-Flamingo-2150 [link] [Kommentare]
Hi all, Lately I have been working on creating a package for Multi Agent RL based drone environments with different objectives, all bundled into a single GitHub repository: https://github.com/tau-intelligence/MuJoCo-drones-gym I am currently trying to organize things for RL community people, with a couple more tools coming soon. But right now, I want to make it useful for the community and hence would love some feedback from different people, about how I could improve it, incorporate more things into it or fix some broken implementation. Also everyone is welcome to raise issues on the repo. Thank you for the support. PS: I have some research publications at RL and ML venues regarding work on RL, though I still want to consider myself as a student of the field and hence would love your help here. submitted by /u/MT1699 [link] [Kommentare]
maybe this should be asked in the Fc26 game subreddit but not sure. Anyway I just saw a video of someone predicting the winner of the world cup using the simulate match feature in the game but he only did it once. Would running this feature 100-1000 times give a significant result ? or is that feature only based on luck ? submitted by /u/Stillane [link] [Kommentare]
