Channels

Batch export, download, and sync your PerplexityAI conversations to Markdown files. The ultimate Chrome Extension to bulk export thousands of searches with Spaces organization and smart deduplication.

Contribute to egeozgul/Incremental-3D-Reconstruction-SfM development by creating an account on GitHub.

Large Language Model (LLM) code agents increasingly resolve repository-level issues by iteratively editing code, invoking tools, and validating candidate patches. In these workflows, agents often write tests on the fly, but the value of this behavior remains unclear. For example, GPT-5.2 writes almost no new tests yet achieves performance comparable to top-ranking agents.This raises a central question: do such tests meaningfully improve issue resolution, or do they mainly mimic a familiar software-development practice while consuming interaction budget? To better understand the role of agent-written tests, we analyze trajectories produced by six strong LLMs on SWE-bench Verified. Our results show that test writing is common, but resolved and unresolved tasks within the same model exhibit similar test-writing frequencies. When tests are written, they mainly serve as observational feedback channels, with value-revealing print statements appearing much more often than assertion-based checks. Based on these insights, we perform a prompt-intervention study by revising the prompts used with four models to either increase or reduce test writing. The results suggest that prompt-induced changes in the volume of agent-written tests do not significantly change final outcomes in this setting. Taken together, these results suggest that current agent-written testing practices reshape process and cost more than final task outcomes.

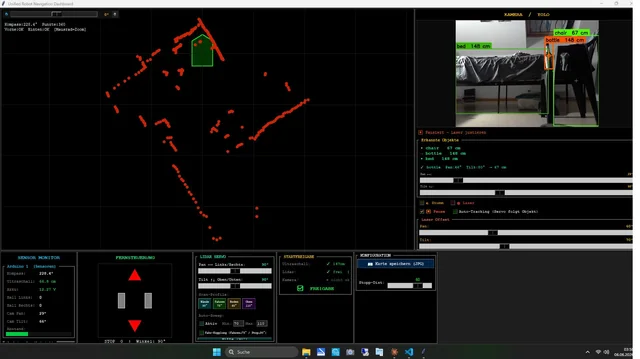
In my previous post was a little showcase of my implementation of the pure pursuit path tracking algorithm for omni-directional robots. One of the missing features is the safe curve approaching. The robot doesn't know the upcoming curve and it won't slow down (enough, at least in the previous implementation). Now I added the feed-forward lookahead that will calculate the slowdown cost based on the total sum of the angle differences of every three pose points in a small set of lookahead points. And the slowdown cost then plugged into the e^-x function and used it to scale the maximum velocity. Now it seems that the robot approaches the curve more smoothly. Additional stuff still needs to be added such as the acceleration limit and the better last pose point brake. If you are interested, you can check it out here over GitHub : https://github.com/E12-CO/iRob_bot_ros2 submitted by /u/TinLethax [link] [Kommentare]
Just came across this turn key modular consumer robotic arm that offers hardware and software integration all in one package. Question: Does anything like this exists for industrial application under $5k, each module made out of stainless steel or aluminum and comes with easy to use software integration (machine vision etc)? submitted by /u/innomind [link] [Kommentare]

Posting an update here with simplified PCB and robustness. Mighty Camera runs VIO on-device in a tiny package. But for it to be useful, you need things like mapping (and later occupancy, loop closure etc). Here is a demo of lightweight mapping which uses VIO pose from Mighty and generates a semi-dense map on host-side in realtime. It’s early but this will be part of the SDK along with other goodies. submitted by /u/twokiloballs [link] [Kommentare]
Hi all, I’m trying to understand how people working with physical AI, embodied AI, robotics, or VLA models think about benchmarks in practice. This is not a product promotion or a request for upvotes. I’m looking for practical perspectives from people who run, read, or rely on benchmark results. A few questions: - Which benchmarks do you actually pay attention to? - Do benchmark scores influence model, policy, or framework choices, or are they mostly sanity checks? - What makes a benchmark result credible to you? - How much do you trust simulated task results compared with real-robot or hardware-in-the-loop results? - What are the biggest red flags when you see a physical AI benchmark claim? I’m especially interested in how people separate useful evidence from leaderboard noise, overfitting, cherry-picked demos, or unclear evaluation protocols. If this is too broad for this subreddit, I’m happy to narrow the question. submitted by /u/Confident_Gas_5266 [link] [Kommentare]
Misu - Wikipedia Jump to content From Wikipedia, the free encyclopedia Grain-based Korean beverage For other uses, see Misu (disambiguation). This article needs additional citations for verification. Please help improve this article by adding citations to reliable sources. Unsourced material may be challenged and removed.Find sources: "Misu" – news · newspapers · books · scholar · JSTOR (May 2014) (Learn how and when to remove this message) Misu Misu-garu (misu powder) Misu (Korean: 미수) is a beverage made from the traditional Korean grain powder misu-garu (미숫가루; misutgaru; 'misu powder'), which is a combination of 7–10 different grains. It is usually served on hot summer days to quench thirst or as an instant nutritious drink for breakfast or as a healthy snack. In a Joseon Dynasty (1392–1897) recipe book, misu was mentioned as stir-fried barley (gu). Gu was a delicacy of that time and easy to serve as one went to travel. Misu is made of glutinous rice and other ingredients, such as barley, yulmu (Coix lacryma-jobi var. ma-yuen), brown rice, black rice, black soybeans, corn, white beans, millet, and sesame seeds, which are ground, roasted and/or steamed, then mixed together. Misugaru is commonly added to water or milk and stirred to make a drink. Sugar or condensed milk can be added as a sweetener. The beverage is high in protein, vitamins, calcium, magnesium, molybdenum, folate, and selenium, and is a dieter's drink, as it is quite filling but low in calories.[1] See also[edit] Chatang – Gruel in Beijing and Tianjin cuisine Gofio – Toasted flour from the Canary Islands Kama (food) – Traditional Finnic dish of mixed cereal flour and milk Rubaboo – PorridgePages displaying short descriptions with no spaces Tsampa – Roasted flour for cereal References[edit] ^ Sue. "Healthy Korean Multi-Grain Shakes – Homemade Misutgaru Latte – My Korean Kitchen". My Korean Kitchen. Retrieved 19 August 2015. vteRice drinksAlcoholic Agkud Amazake Andong soju Apo Ara Awamori Baekse-ju Beopju Brem Cheongju Beopju Chhaang Choujiu Cơm rượu Dansul Gwaha-ju Huangjiu Jiuniang Kuchikamizake Lao khao Lihing Lugdi Makgeolli Mijiu Mirin Nigori Pangasi Raksi Rice baijiu Rice shochu Rượu cần Rượu đế Rượu nếp Sake Sato Shaoxing wine Soju Sonti Sra peang Tamagozake Tapuy Zutho Zu Non-alcoholic Black vinegar Brown rice green tea Brown rice tea Genmaicha Horchata Jūrokucha Mieum Miki Misu Kokkoh Rice milk Rice water Sikhye Sudan Sungnyung List of rice drinks Retrieved from "https://en.wikipedia.org/w/index.php?title=Misu&oldid=1355814791" Categories: Rice drinksKorean cuisineHidden categories: Articles with short descriptionShort description is different from WikidataArticles needing additional references from May 2014All articles needing additional referencesUse dmy dates from July 2024Articles containing Korean-language textPages displaying short descriptions with no spaces via Module:Annotated link Misu Add topic

S&P Global said Thursday it was not changing the requirements for entry into its major indices, dealing a setback to the IPO plans of Elon Musk's SpaceX.

OmnipodKit brings open-source Omnipod 5 support to Loop and Trio. Open beta this summer.
Kean