Channels
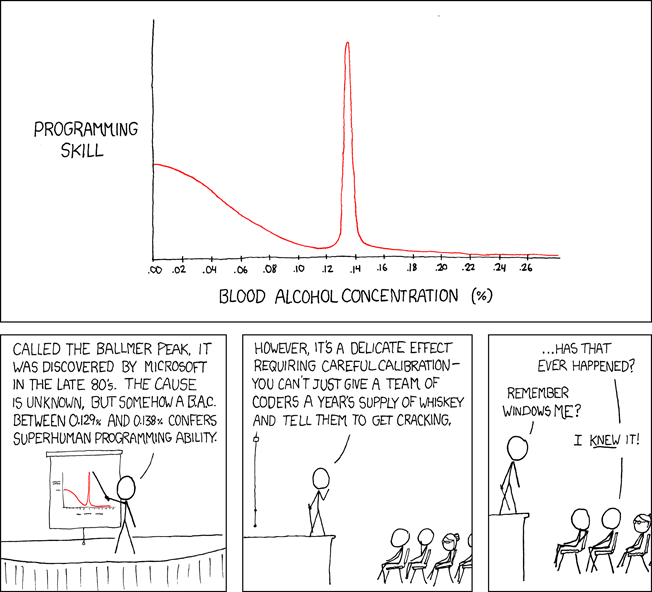
This work is licensed under a Creative Commons Attribution-NonCommercial 2.5 License. This means you're free to copy and share these comics (but not to sell them). More details.
Everyone draws on the same canvas, straight from their browser.
Partition's still there, but good luck seeing it and don't upgrade until fix lands, says team
Natural language endpoint router for market intelligence workflows.

Germany and France failed to come to terms on requirements, apparently bringing Europe’s flagship next gen fighter program to an end. Germany and France have failed to reconcile requirements, apparently bringing Europe’s flagship combat air program to an end.

Curated resources to help you manage and govern your enterprise-scale agents with Agent 365 — the control plane for AI agents.

Free interactive financial education for kids and teens ages 8–17. Learn budgeting, saving, and investing. No teacher needed.

The Digital Embrace | Social Security’s Final Paper Cutoff The digital embrace Social Security shuts the ...

Sequoyah’s syllabary faced suspicion initially, but after a demonstration, his version of “talking leaves” was widely embraced. And then the word spread


Hey everyone! I teach CS and programming at a small school in Syria and I'm in the middle of designing a full 5-year hardware-focused IT curriculum. I'd love some honest feedback from people with hands-on robotics/embedded systems experience. Here's the current plan: - **Grade 7:** Lego Spike Prime + Micro:bit - **Grade 8:** Arduino Uno with multiple sensors - **Grade 9:** Project-based learning with Arduino *(see note below)* - **Grade 10:** ESP32 - **Grade 11:** Advanced ESP32 + Raspberry Pi **Note on Grade 9:** This is the Basic Education Certificate year (think national standardized exams), so the curriculum here is intentionally lighter — more of a consolidation year with small projects rather than introducing heavy new concepts. Students won't have the bandwidth for anything too demanding, so I'm keeping it Arduino-based but project-driven to keep them engaged without piling on. --- **My questions for the community:** **Is this hardware progression age-appropriate?** Students range from roughly 12–17. Does the jump between stages feel right, or are there places where it's too much too soon (or not enough)? **ESP32 in grades 10–11 — good idea or not?** I like it because it covers WiFi/BLE, has plenty of GPIO, and feels like a natural step up from Arduino. But I've heard mixed things about its learning curve and toolchain complexity for high schoolers. What's been your experience? **Are there better alternatives to the ESP32 at that level?** I'm open to suggestions — whether that's staying on the Arduino ecosystem (Nano 33 IoT, Portenta, Uno R4 ?), or something else entirely. Budget is a consideration but not the only one. Any feedback appreciated — curriculum design resources, pitfalls to avoid, or even just "this worked great for my students" stories. Thanks in advance! submitted by /u/Pastalini_Byte [link] [Kommentare]
https://preview.redd.it/w70oeo7mhi6h1.png?width=1875&format=png&auto=webp&s=5d55785b820d0396ae7bbc6d1a76ee7ee410f51a On this day in the last cycle we went lower, just saying. submitted by /u/Own_Chapter9338 [link] [Kommentare]
Full disclosure: this is directional, not a paper. n=120 tasks, one internal evaluator, not peer reviewed. I work at an LLM infrastructure company. This experiment was done on my own time and is not a company claim. Karpathy's framework classifies tasks by verifiability. Can output be mechanically checked? High verifiability tasks like code compilation and structured JSON extraction are safer because the verifier catches errors. Low verifiability tasks like creative writing are riskier. I wondered if high verifiability tasks are also easier in practice. Can a weaker model do them as well as a frontier model if the verifier catches mistakes? Setup was 120 tasks across four categories. Code unit tests, structured extraction, multi hop reasoning, creative summarization. Three models: Claude Sonnet 4.6, GPT 5.5, local Mistral 3 8B via vLLM 0.6.3. Pass rate for the first two, human rating 1 to 5 for the last two. Results were messy. Code unit tests: Sonnet 4.6 94%, GPT 5.5 91%, Mistral 3 8B 87%. With one retry Mistral 3 hit 95%. That surprised me. I expected the gap to be bigger. Structured extraction: Sonnet 4.6 97%, GPT 5.5 94%, Mistral 3 8B 89%. With retry 96%. Also closer than I expected. But here is where it got weird. Sonnet 4.6 initially scored worse than GPT 5.5 on structured extraction, which made no sense. Turns out our JSON schema had an ambiguous nested array that confused Claude's tool use parser. Fixing the schema brought Sonnet to 98%, but I kept the original numbers in the table because the mistake is part of the story. Your verifier is only as good as your schema. Multi hop reasoning: Sonnet 4.6 78%, GPT 5.5 71%, Mistral 3 8B 51%. Retry didn't help. The model would hallucinate reasoning paths consistently. This is where the capability gap was real. Creative summarization: Sonnet 4.6 4.2 out of 5, GPT 5.5 3.9 out of 5, Mistral 3 8B 3.1 out of 5. Expected. Interpretation: high verifiability tasks seem simpler in the sense that weaker model plus verifier can approach frontier performance. Low verifiability tasks show the expected gap. Limitations: n=120 is tiny. Need 10x for confidence. Our verifier is just JSON Schema plus regexes. Constrained decoding might change the calculus entirely. I also didn't control for prompt length well. Any prompt over 8k tokens was excluded because Mistral 3 8B degrades near its limit, which probably skewed the sample. submitted by /u/DragonfruitAlone4497 [link] [Kommentare]