Channels

skill.md is not a replacement for docs, llms.txt, or MCP. It is a compact playbook that tells an agent how to use your product and where to start in your docs.

Batch export, download, and sync your PerplexityAI conversations to Markdown files. The ultimate Chrome Extension to bulk export thousands of searches with Spaces organization and smart deduplication.






Contribute to egeozgul/Incremental-3D-Reconstruction-SfM development by creating an account on GitHub.

Large Language Model (LLM) code agents increasingly resolve repository-level issues by iteratively editing code, invoking tools, and validating candidate patches. In these workflows, agents often write tests on the fly, but the value of this behavior remains unclear. For example, GPT-5.2 writes almost no new tests yet achieves performance comparable to top-ranking agents.This raises a central question: do such tests meaningfully improve issue resolution, or do they mainly mimic a familiar software-development practice while consuming interaction budget? To better understand the role of agent-written tests, we analyze trajectories produced by six strong LLMs on SWE-bench Verified. Our results show that test writing is common, but resolved and unresolved tasks within the same model exhibit similar test-writing frequencies. When tests are written, they mainly serve as observational feedback channels, with value-revealing print statements appearing much more often than assertion-based checks. Based on these insights, we perform a prompt-intervention study by revising the prompts used with four models to either increase or reduce test writing. The results suggest that prompt-induced changes in the volume of agent-written tests do not significantly change final outcomes in this setting. Taken together, these results suggest that current agent-written testing practices reshape process and cost more than final task outcomes.

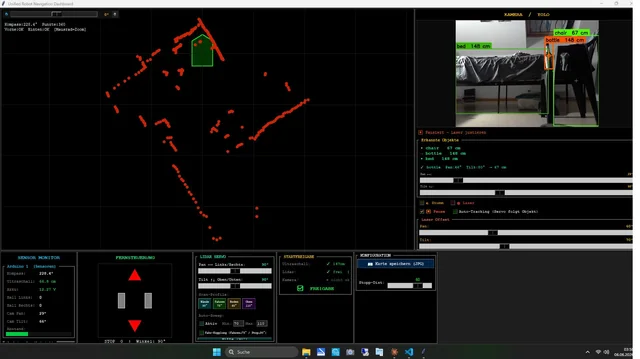
 – Image")

