Channels




Hello r/MachineLearning , I wanted to share the architecture and challenges behind a project I’ve been building called NagaTranslate. The goal is to build a translation and speech pipeline for the low-resource languages of Nagaland, India (currently supporting Nagamese, Ao, and Sema). Since Nagamese and other native Naga languages were primarily oral languages (though recent times have seen a surge in print and digital media in local dialects) with very little standard parallel data, this has been an interesting challenge in low-resource NLP. I’d love to share the technical setup and get your feedback on the architecture and how to improve the pipeline under strict resource constraints. The Architecture & Models 1. Text Translation Approach: Currently, the translation backend utilizes a commercial LLM API with optimized prompts and few-shot examples. Evolution: I initially started with a fine-tuned NLLB (No Language Left Behind) model, but transitioned to the LLM API setup to improve colloquial flow, context handling, and naturalness. The Bottleneck: The long-term goal is to return to self-hosted open-weights models (like a lightweight Llama or Gemma) to make the backend fully independent and free from API costs. However, GPU hosting costs and model quality under extreme resource constraints remain the primary hurdles. 2. Speech Synthesis (TTS) Model: Fine-tuned VITS model on custom Nagamese voice data. Deployment: Hosted on Hugging Face Spaces ZeroGPU behind a secure API layer. 3. Speech Recognition (ASR) Model: Fine-tuned Whisper on custom Nagamese voice records. Deployment: Hosted on Hugging Face Spaces ZeroGPU. Technical Questions & Challenges I’d Love Advice On: Self-Hosting vs. Commercial APIs: For those who have transitioned from commercial APIs back to smaller, self-hosted open-weights models for low-resource translation: How did you bridge the quality gap, particularly for colloquial creoles that aren't well-represented in the base pre-training data? Handling Spelling Variations: Nagamese has no single standardized spelling system, leading to high token variance. What preprocessing, normalization, or robust tokenization approaches have you found effective to handle spelling variations in low-resource setups? TTS/ASR Alignment & Accents: Naga languages has distinct regional accents and phonetic variations. What are the best strategies to fine-tune Whisper or VITS to be robust to non-standard pronunciation when working with a very small voice dataset? I’d appreciate any insights, feedback on the methodology, or pointers to similar low-resource architectures you've found successful. submitted by /u/Material_Dinner_1924 [link] [Kommentare]
Lets say you get a call that an AMR just stopped in middle of the warehouse for no obvious reason. Maybe navigation got stuck, maybe localization drifted, maybe some weird sensor issue. My guess is the process looks something like: check whatever monitoring/dashboard you have ssh into the robot grab logs pull the rosbag for that time period replay in RViz/Foxglove look through planner, localization and perception topics eventually find the issue But honestly I'm not sure if thats how most teams are doing it. For people working on robots in the field: Whats your actual workflow? What tools do you open first? How do you get the logs/bags off the robot? What part takes the longest? What do you wish was easier? Is the workflow above pretty close to reality or is your team doing something completely different? Would love to hear some real examples from incidents you've had to debug recently. submitted by /u/rahulkatiyar1995 [link] [Kommentare]

Om – I hope this finds you well. Your post about Wired tickled just the right group of neurons to make me write something. It’s kind of a rant. But also something I’ve been …

We keep treating a transformation as if it were a transition. It isn't

GSD Task Manager is a private Eisenhower Matrix for web, iPhone, iPad, and Mac. Sort urgent from important, keep tasks on your device, and start without an account.

This is a guest post by Mateusz Maćkowski and Marek Grzelak, co-maintainers of cot.rs and speakers at Rustikon 2026. You can watch their full talk here. In the very beginning, all we wanted to do w
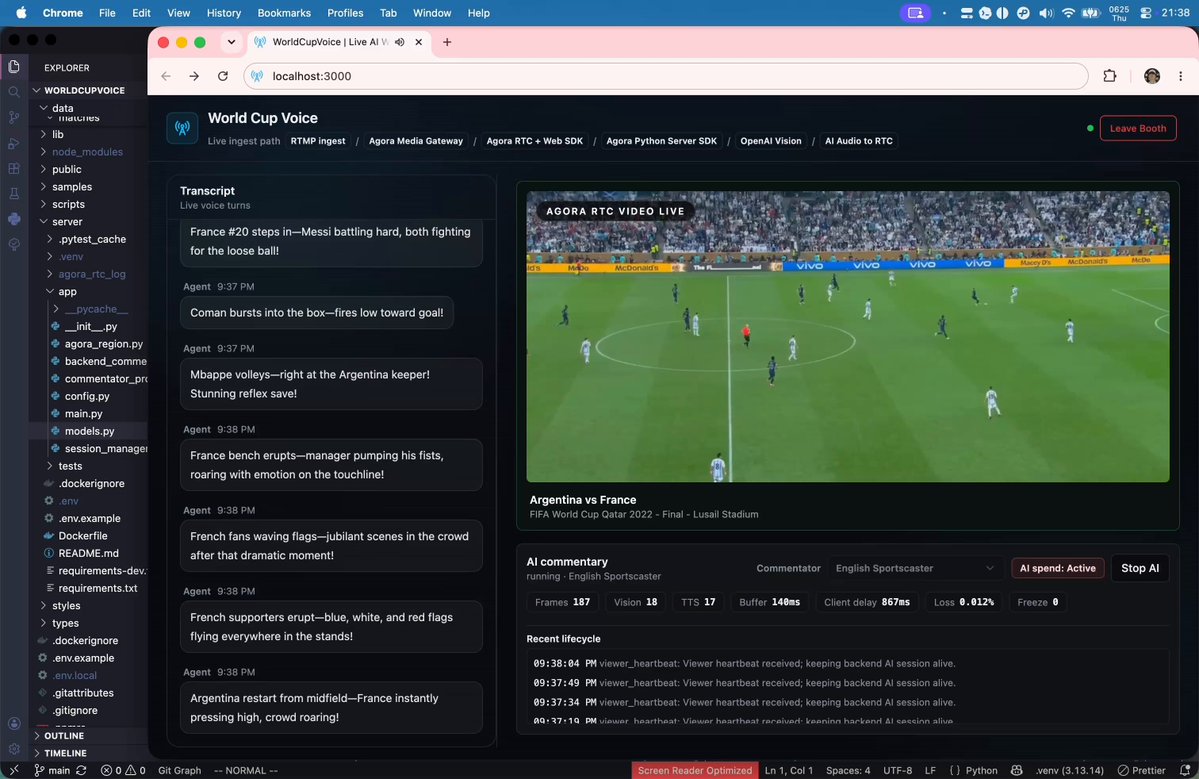
i tried building an AI commentator for the World Cup it watches the live stream as the viewers, samples the newest frames, reads the action, and speaks the play-by-play back into the broadcast in real time here it is calling the 2022 final: https://t.co/WZTVwSl8CY

