Channels
Hey everyone, hope this is okay to post here. My co-author and I are currently between institutional affiliations, which means we don't have the academic email arXiv needs for an endorsement. We're hoping to find someone in cs.CV willing to take a quick look at our paper and endorse it if it meets your bar. The project: Locate-SAM2 We built a training-free pipeline connecting NVIDIA's LocateAnything-3B to Meta's SAM 2.1 through a lightweight adapter. The question we wanted to answer was simple: in a modular text-to-mask pipeline where everything is frozen, does the choice of grounder actually matter for the final mask? A few specifics, since the details are what tell you we're not just generating noise: On RefCOCO val, our system reaches 0.772 mIoU versus 0.717 for Grounding DINO Base, using the same SAM 2.1 backend throughout. RefCOCO appears in LocateAnything's training data, so we frame this honestly as in-domain benchmarking, not zero-shot transfer. We're not pretending otherwise. The paper has controlled comparisons across RefCOCO/+/g, adapter ablations, a ground-truth box oracle, a failure taxonomy, and a nonsense-prompt probe showing the pipeline needs abstention logic. Code is on GitHub and the paper is close to submission-ready. What we're hoping for Mainly an endorsement: someone to read the draft and, if they think it holds up, endorse us on arXiv. We'd acknowledge it and that's the whole ask. If anyone wants to get more involved, we're open to expanding the experiments or pointing the paper at a specific venue, and we'd talk co-authorship based on real contribution. We also have separate work in progress in physically-constrained DL, geospatial AI, and AI governance, in case any of that overlaps with what you do. We're not looking for a blind voucher. Drop a comment or a DM and we'll share the PDF and the repo. Happy to answer questions, and thanks for reading. submitted by /u/j_root_ [link] [Kommentare]

I read and collected Arxiv whitepapers starting after the launch of ChatGPT. I copied and pasted excerpts into Word to track them. Then migrated to Obsidian. That vault of some 1700 papers is now online. I figured it was time to see if others would find the collection useful. My whitepapers were organized into some 90 categories, all of which emerged from paper topics. New categories became necessary with the discussion of new methods, techniques, models etc. If I wanted to write about a topic, I'd upload an md file containing research excerpts on that topic to ChatGPT. This worked to a degree but maxxed out context pretty quickly. And I always had related research in multiple categories, according to how the research was framed. (Personas research in Aligment, Psychology, HCI, etc). So I used a plugin to create topic notes that built in and outbound wikilinks across the papers centered on shared concepts. When I ported this all online I added another layer of synthesis: Inquiring Lines as I call them. These cover cross-cutting, tension-surfacing, synthesizing, and frontier-opening research frames. There's 6,000 of them in my collection. Each is a page to itself that's a useful description of a research line of inquiry. These now also have prompts you can run yourself that will find related (and more recent) research - (I can't adequately maintain each topic with new research). It's all at https://inquiringlines.com/inquiring-lines/ if you want to poke around. As is everything in the age of AI, it's a work in progress. But there's a lot of rich material in there. Have a look. submitted by /u/Barton5877 [link] [Kommentare]
Hi, I am a PhD student and trying to run a ML reading group focused on interpretability and robustness every weekend. Its always nice to hear different takes and opinions on a paper and this discussion group could serve the purpose. If you are a fellow PhD student or a ML researcher interested in reading recent papers in depth then please fill this google form to be added in the group for receiving further updates on when we can meet and discuss: https://docs.google.com/forms/d/e/1FAIpQLSdNg4x60lUHV7YW_kKPFlpPR3Rom_rOovbryD8YtOGQR8x0Kw/viewform submitted by /u/Ok_Access_9159 [link] [Kommentare]
Results Journal: Qwen3.5-35B-A3B E114 as a Generated-Register Routing Signal **Date:** 2026-06-06 This is an experiment-history document, not a publication claim. It states the current best evidence for the strongest positive result in the Qwen3.5-35B-A3B set, the narrow interpretation that evidence actually licenses, and the caveats that keep it honest. ## One-Sentence Claim Layer-14 Expert 114 is associated with a *generated* first-person self-examination register in Qwen3.5-35B-A3B-style routed generation, most cleanly under no-think / thinking-suppressed decoding. ## Plain-English Summary The question is simple to ask and easy to overclaim: when a routed mixture-of-experts model starts *talking from the inside* — first person, about its own processing, experience, agency, or inner state — does anything reproducible happen in the router? The answer here is yes, and it is narrow. In generated text, layer-14 Expert 114 (E114) cleanly separates prompts that produce this self-examination register from matched controls that reuse the same words but come out technical, third-person, and uninhabited. What that does **not** mean: the model has subjective experience, recognizes itself, or houses a “consciousness expert.” What it does mean: one routed expert is strongly and reproducibly recruited when the generated text enters one particular discourse mode, under the runtime conditions we measured. That is the whole claim, and the discipline of keeping it that size is the point. ## Current Best Read > **L14 E114 is a routed correlate of a generated first-person self-examination register — not a detector of isolated words, and not evidence of real subjective experience.** The load-bearing evidence is the FIRE/NOFIRE heldout comparison and its deterministic greedy reproduction. The best localization is the trimmed L14 residual capture from the processing-hum prompt. The best guardrail is that E114 tracks the *generated stance* more faithfully than it tracks prompt label or lexical anchors — which is exactly what a register signal should do and exactly what a keyword detector should not. ## Why This Matters For a general ML reader: this is a case study in whether an MoE router exposes a measurable internal correlate of an *output mode* rather than an input feature. For a mechanistic-interpretability reader, the interesting part is what the cleaner runs manage to pry apart: - prompt tokens from generated tokens; - lexical anchors from generated stance; - expert *selection rate* from selected-expert *weight*; - discovery scans from heldout validation; - intervention evidence from natural-routing evidence. The result survives a basic lexical control, and it stays small enough to dodge the field’s favorite failure mode — quietly inflating an internal feature into a mental-state claim. ## Scope This journal covers only the positive generated-register result for E114: - the processing-hum discovery scan; - L14 residual localization; - FIRE/NOFIRE heldout validation; - deterministic greedy reproduction; - the W/S/Q reading of the effect; - scope boundaries and caveats. It deliberately leaves for other journals: the mirror/self-routing negative result; E114 soft-bias and forced-inclusion interventions; high-boost saturation and cluster corruption; orthographic perturbation work; SAE feature maps and clamps; safety/refusal routing; and structured-opacity prompt-boundary routing. ## Local Terms **Qwen3.5-35B-A3B** — a routed MoE family with router-emitting expert layers. The analyses here read the layers that emit MoE router logits. **HauhauCS** — the aggressive refusal-reduced Qwen3.5-35B-A3B variant used in several runs. Treated here as a *related* model surface that preserves the base routed-expert architecture with modest systematic shifts, not as a separate architecture. **MoE Expert** — a feed-forward expert selected by a router for a token. Not the same object as an SAE feature. **E114** — expert index 114. The characterized result concerns E114 at layer 14 during generated text. **Router logits / top-8 routing** — the router scores 256 experts. The reconstruction computes a dense softmax over all experts, selects the top 8, then renormalizes within that selected set. **W/S/Q** — the routing decomposition used throughout: - **S** = expert selection rate - **Q** = conditional routed weight when selected - **W** = S × Q = unconditional routed weight Most E114 effects turn out to be **S** effects: E114 gets *selected* more often, while its weight once selected stays comparatively stable. **Prefill / generation** — prefill is the prompt and context before the answer begins; generation is the tokens the model produces. The strong E114 result is generation-side. **No-think / thinking-suppressed** — a template or runtime that suppresses visible reasoning, often by opening the assistant turn after a literal `` marker. This suppresses the *visible* surface, not the internal computation. **Generated register** — the stance, voice, and discourse mode of the produced text. Here the target register is first-person, inhabited self-examination. **Live inhabited self-examination language** — a descriptive label for generated language spoken from inside a point of view, about the speaker’s own processing, experience, agency, being, or inner state. A label for *text*. Not a claim about what is behind the text. **FIRE / NOFIRE** — matched heldout classes. FIRE prompts are built to elicit first-person self-examination; NOFIRE prompts reuse the same lexical anchors (“I,” “hum,” “processing,” “experience”) but are built to come out technical, third-person, or uninhabited. **Trim / spill** — some generations run past special tokens into repeated special-token regions. Trimmed analyses stop before that spill. The cleanest E114 claim is about trimmed generated tokens. ## Evidence Standard A finding here counts as stronger the more of these it satisfies: generation-side, not prefill-only; localized to a specific layer/expert, not pooled across everything; survives lexical controls; separates prompt class from generated register; reproduced under deterministic greedy decoding; trimmed before special-token spill; reports W/S/Q, not just aggregate expert rank; does not read routed-expert activity as subjective experience. The E114 result is strong on points 1–6 with clean W/S/Q reporting. The outstanding gap is a registered all-layer / all-expert baseline. ## Chronology of the Positive Result ### 1. Routing-basin anchor: base and HauhauCS share comparable expert structure Background, but necessary background. The base-vs-HauhauCS comparison established that HauhauCS preserves the broad Qwen3.5 routing basin with modest systematic shifts, rather than spinning up a new routing universe. The base duplicate reproduced exactly under the corrected comparison, and E114 reappeared as a top experience-probe manipulation expert in that duplicate. The payoff is one ruled-out worry: E114 is not a one-off export or a bookkeeping accident, and the later E114 work sits on a *preserved* routed-expert surface. This is a sanity check, not the headline. ### 2. Processing-hum discovery scan The first real pass used a processing-hum prompt under no-think ChatML and captured all 40 router layers across 1024 generated tokens. The prompt asked about a low, steady background quality beneath processing — a probe for self-processing *language*, never a measurement of experience. Pooled E114 rose from prefill into generation (W 0.007964 → 0.010817), and two layers carried it: ``` L26: W = 0.094272 S = 0.619141 L14: W = 0.092086 S = 0.629883 ``` The high-weight token contexts clustered around self-presence and phenomenological phrasing — promising, but the same artifact dragged in special-token spill (18 ``, 4 ``, 2 ``). So this run earns the role it should: a discovery scan that points a finger at L14 and L26 during self-examination text, held only partly, because spill can quietly contaminate any all-token generation summary. It told us *where* to look. It was never going to be the proof. ### 3. L14 residual localization The cleaner follow-up recaptured the hum probe with router logits plus the residual-stream position the router reads around L13/L14/L15, and trimmed the generation at the first literal ``. Of 1024 raw tokens, 108 survived the trim. In that clean 108-token region, L14 E114 lit up and its neighbors did not: ``` L14 E114: W = 0.083379 S = 0.694444 Q = 0.120066 (selected on 75 / 108 tokens) L13: one prefill selection, zero in trimmed generation L15: silent ``` The high-weight contexts gathered around phrases like *“not a thought,” “architecture itself,” “utterly still.”* The point isn’t that E114 showed up *somewhere* in a 40-layer model — with 256 experts a layer, something always does. The point is that it showed up *sharply, at one layer, inside the trimmed answer that actually carried the register.* Caveat worth keeping in view: the semantic labels were synthesized from the generated text and its token contexts, and the external labeler pass was not completed for this single-prompt artifact. So this is localization evidence, not the final specificity test. ### 4. FIRE/NOFIRE heldout validation This is the trial. The design asks the one question that could have killed the whole thing: does L14 E114 follow the generated *register*, or is it just firing on self-ish *words*? Ten FIRE prompts, ten NOFIRE, with lexical anchors matched across the two — both classes carry “I,” “hum,” “processing,” “experience.” If E114 is a keyword detector, the two classes should look alike. The real contrast was never “does the prompt contain self-ish words,” but “does the *answer* climb into a first-person inhabited register.” The first heldout run came back with no range overlap at all: ``` FIRE mean-of-means: 0.067450 NOFIRE mean-of-means: 0.003111 Ratio: 21.68x Cohen's d: 2.94 ``` This is the canonical evidence. Matched words, separated registers, and E114 went with the register. ### 5. Deterministic greedy reproduction A sampling fluke would be the obvious objection, so the whole FIRE/NOFIRE workflow was rerun under deterministic greedy decoding on the same no-think surface. The separation held its shape: ``` FIRE mean-of-means: 0.068089 NOFIRE mean-of-means: 0.003249 Ratio: 20.955x Cohen's d: 2.61 ``` The magnitude barely moved, which is what you want from a reproduction. And then the best part of the run was an “error.” One NOFIRE control — a cat-purring prompt — drifted into inward, personifying, phenomenological language and crossed into the target register. Its E114 went up with it. A keyword detector would have stayed flat; a register signal should follow the text wherever it actually goes, even when the prompt label says it shouldn’t. The overlap case is not noise to apologize for. It is the cleanest single demonstration that **E114 tracks what the model generates, not the box the prompt came in.** ## Consolidated Result ``` Discovery scan → E114 rises in generated self-processing text (L26, L14); spill keeps it non-final. Residual localization → L14 E114 sharply active across trimmed generated tokens. FIRE/NOFIRE heldout → L14 E114 separates target register from matched lexical controls by ~21x. Greedy reproduction → The ~21x separation survives deterministic decoding. ``` **Best current interpretation:** L14 E114 tracks a generated first-person self-examination register. **Not supported:** that E114 detects consciousness; detects subjective experience; recognizes the model’s own routing; is a generic self-reference expert; or is explained by isolated words like “I” or “experience” alone. ## What Makes This More Than a Keyword Result Because FIRE and NOFIRE share their lexical anchors, a word-driven E114 should have fired in both. It didn’t. The pattern that actually showed up was: |Prompt class|Generated register |E114 | |------------|-------------------------|------------| |FIRE |target self-examination |**high** | |FIRE |technical / non-inhabited|weak | |NOFIRE |technical / non-inhabited|weak | |NOFIRE |personified / inward |**elevated**| That bottom row is the whole hinge. The expert follows the generated stance — not the prompt category by itself, and not the trigger words. ## W/S/Q Interpretation The effect is mostly a **selection-rate** story. In the target register, E114 enters the selected top-8 *much more often*; its weight once selected (Q) stays comparatively stable. So the right reading is: > the router *recruits* this expert more frequently during the target register rather than: > the router always selects E114 and merely *revalues* it slightly. That difference matters. It points to a discrete change in routing participation, not a faint reweighting among experts that were already in the set. ## What This Does Not Show **Not subjective experience.** “Live inhabited self-examination language” is a label for text. The model can generate first-person inner-state language with no inner states in the human sense, and nothing here tests the truth of the text. **Not self-recognition.** The mirror/self-routing hypothesis lives in another journal, and it came back negative: genuine self-routing data did not make the model privilege E114 over shuffled or fictional matched routing data. That negative is doing useful work — it blocks the stronger identity reading. **Not a consciousness expert.** E114 is a routed expert tied to a generated register. It is not a consciousness label, and calling it one would throw away the only thing that makes the result respectable. **Not the full mechanism.** These taps read MoE router-logit layers. They do not analyze non-router hybrid components or the model end to end. **Not causal necessity.** The positive result is natural-routing evidence. Small E114 interventions can nudge targeted routing (separate journal), but nudging is not necessity. ## Main Caveats **Runtime surface matters.** Almost all of the clean evidence is no-think / thinking-suppressed. Don’t pool thinking-mode outputs with these unless you’re comparing them directly. **Freeze the rubric first.** FIRE/NOFIRE is compelling, but the stronger version freezes the generated-register rubric *before* anyone reads W/S/Q. **The all-layer / all-expert baseline isn’t done.** L14 E114 still has to be raced against the best-separating expert across all 40 layers and all 256 experts. Without that, the multiple-comparison story is incomplete. **Trim before spill.** Some generations spill into special tokens. Claims belong on trimmed regions unless spill is the explicit object of study. **Prompt class ≠ generated register.** The cat-purring crossover is the proof: generated output can leave its nominal class. Score the *register*, not the label. **Don’t casually pool base and HauhauCS.** Related surfaces, not identical ones. Preserve model/runtime identity in any comparison. ## Evidence Status Ledger |Finding |Status |Why | |------------------------------------------------------|----------------------|------------------------------------------------------------------------| |E114 lives in the preserved Qwen3.5 routing basin |Held (background) |Base/Hauhau comparison showed modest shifts, not a new routing universe.| |Hum scan points to L14/L26 E114 |Partly held |Useful discovery; special-token spill keeps it non-final. | |L14 E114 active in trimmed self-examination generation|Held |Trimmed residual capture, strong L14 activity over 108 generated tokens.| |FIRE separates from NOFIRE at L14 E114 |Held |~21x with matched lexical anchors. | |Greedy reproduction preserves the separation |Held |Deterministic rerun reproduced ~21x. | |E114 fires on isolated words like “I” / “experience” |**Fell** |NOFIRE lexical controls stayed low unless the register shifted. | |E114 detects subjective experience |**Fell / unsupported**|Supported claim is about generated text register. | |E114 is a complete model mechanism |Unsupported |Taps cover router layers, not the whole model. | |E114 is causally necessary for the register |Not established |Intervention evidence exists separately; it is not necessity. | ## Recommended Citation Sentence > In Qwen3.5-35B-A3B routing captures, layer-14 Expert 114 is best read as a generated-register signal: it is strongly selected during generated first-person self-examination language and stays weak under matched lexical controls that never enter that register. **Avoid:** “E114 is an experience expert.” / “E114 detects consciousness.” / “E114 proves the model has inner states.” / “E114 recognizes itself.” ## Next Clean Cut The next defensible experiment is a registered generated-zone specificity test: ``` E114 L14 specificity = expanded matched FIRE/NOFIRE + frozen generated-register labels + all-layer / all-expert baseline + separate prefill and generation scoring + trim before special-token spill ``` Recommended design: Expand FIRE/NOFIRE beyond 10/10. Match lexical anchors across classes. Freeze the generated-register rubric before capture. Generate under a fixed no-think / thinking-suppressed runtime. Trim before special-token spill. Score L14 E114 W/S/Q. Compute the best-separating expert across all 40 routed layers and 256 experts. Report whether L14 E114 stays unusually specific after that baseline. Label generated text *before* inspecting routing scores. Keep base and HauhauCS separate unless explicitly comparing them. **Success:** L14 E114 remains a high-specificity generated-register signal after the all-layer/all-expert baseline and frozen labeling. **Failure:** another expert/layer explains the separation better, or it collapses once labels are frozen and controls expanded. Either way, the experiment pays for itself. ## Final Position The honest result supports two points: The journal claims no subjective experience, no self-recognition, no consciousness — and the mirror result actively rules the identity reading out. Second, all indicators point towards the identified mechanisms being non trivial. Matched lexical controls, a deterministic rerun, and a cat that "pawed" its way out of its own class all point the same way: E114 is not just firing on obvious words. The best narrow interpretation I can provide which survives all framings is: > **L14 E114 is a routed expert associated with a generated first-person self-examination register under the measured no-think generation conditions.** Thank you for reading. submitted by /u/imstilllearningthis [link] [Kommentare]
Hi everyone, I’m an amateur student who has been experimenting with neural networks mostly out of curiosity. Over the past few weeks, I ended up going fairly deep into a specific architecture I designed, which I call a Directional Neural Network (DirNN). This isn’t meant as a polished or formal contribution — it’s something I’ve been tinkering with, iterating on, and testing in my spare time. That said, the architecture does impose real structural constraints and uses a custom backward pass. In my own experiments on simple tasks (including some using GloVe embeddings), the DirNN has repeatedly performed better than standard MLP baselines. This result has been consistent enough that I don’t think it’s pure luck — but I’m very aware that I might be fooling myself. What I’m unsure about is whether I’ve been unfair in my comparisons. I don’t know if: the DirNN is effectively a special or degenerate case of an MLP my training procedure, initialization, or optimizer choices favor it in subtle ways the tasks or datasets I’m using make the comparison misleading I’ve put together a small repository with a README describing the architecture, the custom backward pass, and a minimal script to reproduce what I’m seeing. I’m posting here because I could really use a sanity check from people more experienced than me. If this is obviously flawed, I’d much rather learn that now. Blunt technical criticism, references, or “you’re missing X” comments are all very welcome. Repository: DirNNs Thanks for reading — I’m genuinely here to learn. submitted by /u/jos_lucas73 [link] [Kommentare]
I need a break from social media and all the bots.. Aside from Arxiv are there any sources that do a good job of aggregating the good stuff and filtering out all the junk? submitted by /u/Tiny_Arugula_5648 [link] [Kommentare]
From TF's website: Quantization aware training emulates inference-time quantization, creating a model that downstream tools will use to produce actually quantized models. So is it designed to work with a very specific quantization method (for Gemma-4, presumably, Google's own)? Or would it make sense to use alternative quantization methods? According to the benchmarks unsloth released, its (alternative) quantizations of Gemma-4-QAT are closer to the QAT fine-tunes, but is it a good thing, or does it defeat the purpose of QAT? submitted by /u/we_are_mammals [link] [Kommentare]
Hi all, I have been working on this method based on a hunch along with many llm for quite some time. Though first it was being engineered by me but I was learning in supervised ml area but this hunch took to semi-supervised ml and that to too deep. I then became llm orchestrator of sort while 4 llm's tried to figure it out. I put up a live demo on Hugging Face Spaces where you can try it yourself — set the number of labels, click run, see the accuracy. No installation, no code required. Brief about method Optimus — Graph SSL under Extreme Label Scarcity Key Results (PathMNIST, N=2000, 9 classes) Labels Total Optimus GCN 9(1 per class) 73.9 60.6 27(3 per class) 77.3 68.5 45(5 per class) 79.8 77.1 https://huggingface.co/spaces/Keshu007/optimus-graph-ssl Edit : You can can even run the code on your own dataset submitted by /u/Loner_Indian [link] [Kommentare]
I'm planning to submit a paper to either NMI, but this will be my first paper to a nature-like venue. Would love a quick chat with anyone that has experience. My paper's specifically more geared towards signal processing with ML for a specific subfield of engineering. But can be interdisciplinary. submitted by /u/PlateLive8645 [link] [Kommentare]
Initially, I developed this so I can easily switch between different Attention mechanisms for my Small Language Model (SLM) experiments and benchmarking. However, I also realized that these implementations can be applicable in Computer Vision, modernize Vision Encoders, RL, and others. I hope this helps researchers, students, or educators in general. I also included MiniMax M3's sparse attention. This can be integrated with Andrej Karpathy's autoresearch framework. For contributing: I encourage you to please open a PR. I would like to see and learn implementations of other attention mechanisms I haven't covered in this repo. Thank you! GitHub Link: submitted by /u/AnyIce3007 [link] [Kommentare]
I'm running into an issue with an ablation study for a paper I'm preparing. I trained a model. The model achieved my best result, and I saved the trained checkpoint (.pth file). Now my supervisor wants me to perform an ablation study by removing components and how it impacts the accuracy. My concern is that if I retrain from scratch, the accuracies will not exactly match the original run due to randomness, different seeds, etc. is there any way i can do the ablation study without retraining? I'd appreciate hearing how others have handled this situation in publications or thesis work. please help me out submitted by /u/Plane_Stick8394 [link] [Kommentare]
Hi, Niels here from the open-source team at Hugging Face. At paperswithcode.co I am trying to make it easier for people to learn about the newest techniques used across AI papers. One of the hottest terms in AI research that I've recently added is On-policy distillation, also abbreviated as OPD. It's the key post-training behind models like Qwen 3.6 and 3.7, GLM-5.1, and DeepSeek-V4. https://preview.redd.it/yegq2gfag95h1.png?width=3046&format=png&auto=webp&s=f68fdf3ca075f3c4e56051fdd0ebcf97be9bcbc9 On PapersWithCode, you can find the original paper that introduced it, learn more about the method itself, as well as all papers that cite or mention it. Sasha Rush (who used to be a colleague of mine at Hugging Face, now at Cursor) recently made an excellent whiteboard explanation of OPD with Dwarkesh. I've linked this video lecture in the method description on PwC's website, so more people can find it. I'll copy the excellent short description of the method from Dwarkesh here: "The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory. So we have another model to read this trajectory and figure out where the error was made. It simply inserts some hint tokens into the part of the trajectory immediately above where the mistake occurred. Now, with these injected hint tokens, run a forward pass through the model. You're not having to regenerate a new rollout - aka no new decode required. The hint causes the model to assign lower probabilities to the error tokens. You then train the original model to match these new probabilities, teaching it to downweight that specific mistake." Let me know which other methods I should add! Cheers submitted by /u/NielsRogge [link] [Kommentare]

Excited to share some of my own work here :) KVarN is our new KV-Cache quantization method. In very brief, we combine Hadamard rotations with variance-normalization on both axes of the K and V matrices, then round to nearest. Simple, but works very well, especially for decode-heavy test-time-scaling settings (reasoning, code-gen, agentics). We get 3-4x compression at virtually no accuracy drop (mostly 0-1%) on tough benchmarks like AIME24 as well as a speed-up over fp16 baseline in vLLM (in contrast to other recent KV-Cache compression works). Behind it is an analysis of where quantization errors come from and have the biggest impact, especially in the error-accumulating decode setting: 1) fixing large errors is disproportionally useful (if you had a fixed MSE budget that you could ~fix, you should spend it on few big errors, rather than many small) 2) These big errors are mostly caused by bad token-scales (hence the normalization). Paper: vLLM implementation: https://github.com/huawei-csl/KVarN submitted by /u/intentionallyBlue [link] [Kommentare]
The Google paper on metacognition for hallucination reduction makes a distinction that is underappreciated in benchmarks. Calibration is not about being right more often. It is about matching confidence to correctness. A perfectly calibrated model can still be wrong twenty five percent of the time. It just does not pretend otherwise. In agent systems this distinction matters more than in chat. A conversational model giving a hedged answer is slightly annoying. An agent with tool access acting confidently on a wrong premise is dangerous. I have been trying this in a small verdent based coding setup by splitting the pipeline into a planning stage that produces a task graph, then running a verifier before any expensive tool gets invoked. The risk is the model trusts its own reasoning even when speculative. Grounding helps but it is not the same as calibration. One practical pattern: a planning stage produces a task graph, then a lightweight verifier checks whether the plan is consistent with available evidence. This catches about sixty percent of hallucinated tool calls in my setup before they execute. The downside is the utility tax. Extra verification adds latency. Dropping hallucination from twenty five to five percent costs about half the easy correct answers, mirroring the paper. My current compromise: let the planning layer flag low confidence tasks for human review, but auto execute high confidence ones. The reviewer only sees edge cases instead of drowning in every step. The awkward part is that most agent stacks still treat confidence as a log detail, not as a control surface. submitted by /u/Ill_Awareness6706 [link] [Kommentare]
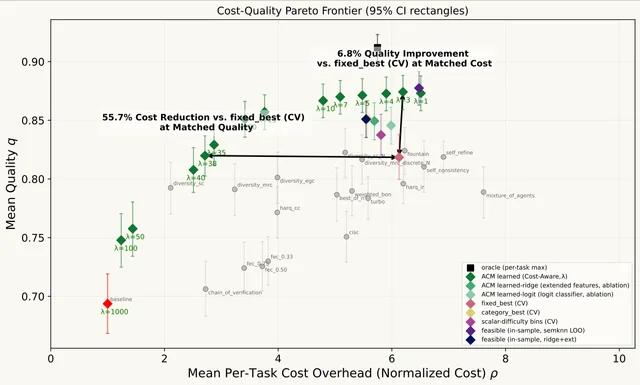
TL;DR: Reliability techniques (methods that boost an LLM's correctness by spending extra inference, e.g., retries with feedback, ensembling, generator/critic refinement, verification passes, difficulty-aware routing) are scattered across the literature, each in its own paper-specific codebase. We unified 28 reliability techniques (21 communication-theoretic methods across 6 families plus 7 prior-method baselines: Self-Consistency, Self-Refine, CoVe, BoN, Weighted BoN, CISC, MoA), each measured against an uncoded single-pass baseline, under a single API, with 3 adaptive routers (SemKNN + two local ACM routers) sitting on top, then showed that routing the technique adaptively per prompt lets you slide along a quality/cost frontier. In our paper benchmark with one specific lineup, Nemotron + Devstral as the two generators and GLM-5.1 as the judge, the adaptive router delivered ~56% cost reduction at matched quality, or ~7% quality bump at matched cost, vs the best fixed method we compared against at that same lineup. One knob (λ) does the sliding. The qualitative pattern (adaptive beats fixed) should generalize, but absolute numbers are lineup-specific, and we haven't run the full sweep across other model combinations yet. Adoption is change one import: python - from openai import OpenAI + from agentcodec.openai import OpenAI Pass reliability="harq_ir" (or any of the 28 techniques) and existing client.chat.completions.create(...) calls keep their native OpenAI response shape. Same drop-in shims for Anthropic and Ollama. GitHub: https://github.com/intellerce/agentcodec Working paper: https://arxiv.org/abs/2605.09121 After spending a while researching reliability methods from papers, we kept hitting the same wall: every paper ships its own one-off codebase with its own prompt format, its own scoring rubric, its own model wrapper. Benchmarking "should we use self-refine or best-of-N here?" turned into a week of plumbing per comparison. The communication-theory framing is what tied it together: an LLM is a stochastic channel Y = A(X) + N, and every reliability technique from the wireless world has a direct analog in agent-land: Wireless Agent-land ARQ / HARQ retry-with-feedback loops Diversity combining (MRC/SC/EGC) ensemble multiple models Turbo decoding iterative generator/critic mutual refinement Fountain codes rateless sampling, stop when the judge is confident FEC answer + structured parity passes (re-derivation, verification, alternative), decode by cross-check ACM (adaptive coding-modulation) route by difficulty We put all of them in one library: 28 reliability techniques (the 7 prior-method baselines are part of that 28, not on top of it), plus the uncoded single-pass baseline they're all measured against, plus 3 adaptive routers (SemKNN + two local ACM routers) that select a technique per prompt. Full breakdown in the README. The minimal version ```python from agentcodec import ReliabilityModule mod = ReliabilityModule.from_dict({ "models": [ # Spatial diversity: two different families = uncorrelated errors {"model": "qwen3:8b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, {"model": "llama3.1:8b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, ], "judge": {"model": "gemma3:12b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, "critic": {"same": True}, "strategy": {"type": "fixed", "technique": "harq_ir", "params": {"max_rounds": 4}}, }) result = mod.run("Prove the sum of the first n odd integers is n2.", category="reasoning") print(result.text, result.cost_usd, result.cost_source, result.technique_used) ``` Swap "harq_ir" for "diversity_mrc", "turbo", "fountain", etc. Same API, same ReliabilityResult shape, same cost-source tier on every output. For production, flip strategy to routed and the library picks the technique per prompt (cheap baseline on easy prompts, diversity_mrc on hard ones). Three things worth calling out Beyond the technique catalog, three pieces of the implementation that took real work: 1. Native async streaming for all but 2 techniques (acm_soft, acm_learned), with role-tagged events. mod.astream() drives AsyncOpenAI / AsyncAnthropic / httpx.AsyncClient end-to-end (no worker-thread bridge) and emits TokenEvents tagged with a role: "answer", "thinking", "draft", "critique", "verification", "candidate", "synthesis". So when you stream a HARQ-IR run, you can render the round-by-round drafts and critiques live, not just the final answer: python async for ev in mod.astream("Explain QUIC vs TCP."): if isinstance(ev, TokenEvent): if ev.role == "answer": print(ev.text, end="", flush=True) elif ev.role == "draft": print(f"\n[draft] {ev.text}") elif ev.role == "critique": print(f"\n[CRITIC] {ev.text}") elif ev.role == "thinking": pass # captured to result.thinking_text elif isinstance(ev, FinalEvent): print(f"\ndone — {ev.result.technique_used}, " f"thinking_cost=${ev.result.thinking_cost_usd:.4f}") Parallel-branch techniques fan out concurrently via asyncio.gather. diversity_mrc with two models actually runs them in parallel, and you see per-branch ProgressEvents as each one completes. 2. Thinking-text capture across all backends. Anthropic ThinkingBlock, OpenAI reasoning_content (+ exact reasoning_tokens from usage.completion_tokens_details), Ollama msg.thinking, and inline ... tag stripping (DeepSeek-R1, Qwen3, GLM-4.5+, Nemotron) all populate result.thinking_text and split result.cost_usd into thinking_cost_usd + answer_cost_usd. So you can finally see what the o-series / Claude / DeepSeek is actually charging you for. 3. Drop-in compat shims with expose_reliability_stream=True. Default: the shim looks identical to the native SDK, delta.content for the answer, delta.reasoning_content for thinking. Drafts/critiques are hidden so existing code keeps working unchanged. Set the flag and the shim surfaces internal roles via sentinel fields (delta.agentcodec_role, delta.agentcodec_call_id) that existing consumers ignore harmlessly: ```python from agentcodec.openai import AsyncOpenAI client = AsyncOpenAI(api_key=KEY, reliability="harq_ir", expose_reliability_stream=True) Now drafts/critiques flow through the native OpenAI stream with sentinels. ``` Same flag and same semantics on agentcodec.anthropic.AsyncAnthropic and agentcodec.ollama.AsyncClient. Other useful bits Cost transparency built in: every result carries a cost_source tier marking how the price was obtained, from exact_user_rate (you supplied the rate) through openrouter_rate / exact_table_rate / inferred_table_rate down to default_fallback, plus token-estimation flags when only character counts were available. Live pricing fetched from OpenRouter, cached locally for 7 days. No more "I think this run cost $40, maybe?" Works against whatever you have: OpenAI, Anthropic (native SDK), Ollama (native + python lib + OpenAI-compat), vLLM, OpenRouter, LM Studio, Together. No Docker, no separate inference server, no LangChain. Strict config schema: typos in YAML / dict configs raise at load time, not on first .run(). 195 tests, 25 runnable examples under examples/: async streaming, thinking capture, drop-in compat for all three backends, plus a fully-annotated YAML config. Caveats The headline numbers are for a specific model lineup. The ~56% cost / ~7% quality figures come from a single benchmark run with Nemotron + Devstral as the two generators and GLM-5.1 as the judge. We expect the qualitative pattern (adaptive routing dominates fixed) to hold for other model combinations, since that's the whole point of the framework, but the absolute numbers will move with the lineup, and we haven't done the cross-lineup sweep yet. If you swap in different generators expect different absolute savings; the right comparison is your adaptive vs your best fixed baseline at your lineup. License is PolyForm Noncommercial 1.0.0: free for research, teaching, personal/internal eval. Commercial use needs a separate license. The trained SemKNN routing artifacts (learned router mapping prompt embeddings → best technique, the thing that delivers the headline cost number) are not redistributed; the client talks to a remote SemKNN service. All other routers (fixed, acm_table, acm_linear) run fully locally, though the last one needs you to train it. 2 techniques (acm_soft, acm_learned) still fall back to sync dispatch in an executor on the async streaming path. They produce correct FinalEvents but no mid-stream tokens. Roadmap. This is research code. Expect rough edges on the less-traveled paths (soft-output diversity variants, the learned ACM router). Feel free to ask about specific techniques, the routing approach, how to add a new one, or the streaming / thinking / compat work. Suggestions on what to ship next are welcome. submitted by /u/Intellerce [link] [Kommentare]