Channels

https://preview.redd.it/wepjpyo2oj5h1.png?width=1288&format=png&auto=webp&s=4c1e037e4de37998ec007004d65c70158a1d90f8 Ich spiele aktuell Warera.io und suche Mitspieler aus der deutschen Community. Im Spiel ist aktuell eine Situation entstanden, in der Deutschland zunehmend unter Druck gerät. Gleichzeitig stehen wir starken Gegnern gegenüber, die im Spielverlauf deutlich aktiver und besser organisiert sind. Aktuell ist Deutschland von Frankreich besetzt mit Hilfe der Ägypter. Deshalb suche ich Spieler, die sich einmal am Tag kurz einloggen, um etwas Schaden zu machen und das Team zu unterstützen. Das ist im Grunde Genommen das ganze Spielprinzip. Es geht dabei wirklich nicht um großen Zeitaufwand ein paar Minuten reichen bereits aus. Es ist ein einfaches Browsergame ohne p2w ohne Werbung. Hat extrem viel von r/places Da jeder hier Artikel schreiben kann m spiel ist das im Grunde genommen fast nur ein Meme-War. Gute Unterhaltung. Kämpfen wir gegen die Italiener dann posten wir in Artikeln z.b. zerbrochene Spaghetti ^^ Nur um mal so die community zu beschreiben. Aktuell sind wir von den Franzosen besetzt und von den Dänen, wie man im Bild sieht. Befreundet sind wir in der so genannten B.E.E.R Koalition mit Schweden, Britten, Irländern, Finnen, und Norwegern. Wir planen aktuell unser Aufstieg und die Wiedererlangung der Suverän.... meh wir machen den Aufstand... Was ich noch sagen kann: Kein p2w niemals, das hat sich der Entwickler auf die Fahne geschrieben Nirgendswo Werbung Keine Kosten Riesig deutsche Community. Memes Comics. Clips.. usw.... Es ist einfach nur ein Länderkampf. Und früher oder später gewinnen wir. Hoffentlich. Aber dafür bruachen wir jeden Deutschen. submitted by /u/Rio1339 [link] [Kommentare]









Hi, Niels here from the open-source team at Hugging Face. At paperswithcode.co I am trying to make it easier for people to learn about the newest techniques used across AI papers. One of the hottest terms in AI research that I've recently added is On-policy distillation, also abbreviated as OPD. It's the key post-training behind models like Qwen 3.6 and 3.7, GLM-5.1, and DeepSeek-V4. https://preview.redd.it/yegq2gfag95h1.png?width=3046&format=png&auto=webp&s=f68fdf3ca075f3c4e56051fdd0ebcf97be9bcbc9 On PapersWithCode, you can find the original paper that introduced it, learn more about the method itself, as well as all papers that cite or mention it. Sasha Rush (who used to be a colleague of mine at Hugging Face, now at Cursor) recently made an excellent whiteboard explanation of OPD with Dwarkesh. I've linked this video lecture in the method description on PwC's website, so more people can find it. I'll copy the excellent short description of the method from Dwarkesh here: "The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory. So we have another model to read this trajectory and figure out where the error was made. It simply inserts some hint tokens into the part of the trajectory immediately above where the mistake occurred. Now, with these injected hint tokens, run a forward pass through the model. You're not having to regenerate a new rollout - aka no new decode required. The hint causes the model to assign lower probabilities to the error tokens. You then train the original model to match these new probabilities, teaching it to downweight that specific mistake." Let me know which other methods I should add! Cheers submitted by /u/NielsRogge [link] [Kommentare]
The Google paper on metacognition for hallucination reduction makes a distinction that is underappreciated in benchmarks. Calibration is not about being right more often. It is about matching confidence to correctness. A perfectly calibrated model can still be wrong twenty five percent of the time. It just does not pretend otherwise. In agent systems this distinction matters more than in chat. A conversational model giving a hedged answer is slightly annoying. An agent with tool access acting confidently on a wrong premise is dangerous. I have been trying this in a small verdent based coding setup by splitting the pipeline into a planning stage that produces a task graph, then running a verifier before any expensive tool gets invoked. The risk is the model trusts its own reasoning even when speculative. Grounding helps but it is not the same as calibration. One practical pattern: a planning stage produces a task graph, then a lightweight verifier checks whether the plan is consistent with available evidence. This catches about sixty percent of hallucinated tool calls in my setup before they execute. The downside is the utility tax. Extra verification adds latency. Dropping hallucination from twenty five to five percent costs about half the easy correct answers, mirroring the paper. My current compromise: let the planning layer flag low confidence tasks for human review, but auto execute high confidence ones. The reviewer only sees edge cases instead of drowning in every step. The awkward part is that most agent stacks still treat confidence as a log detail, not as a control surface. submitted by /u/Ill_Awareness6706 [link] [Kommentare]
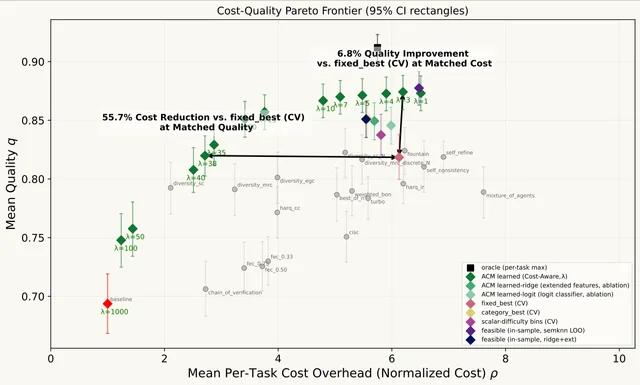
TL;DR: Reliability techniques (methods that boost an LLM's correctness by spending extra inference, e.g., retries with feedback, ensembling, generator/critic refinement, verification passes, difficulty-aware routing) are scattered across the literature, each in its own paper-specific codebase. We unified 28 reliability techniques (21 communication-theoretic methods across 6 families plus 7 prior-method baselines: Self-Consistency, Self-Refine, CoVe, BoN, Weighted BoN, CISC, MoA), each measured against an uncoded single-pass baseline, under a single API, with 3 adaptive routers (SemKNN + two local ACM routers) sitting on top, then showed that routing the technique adaptively per prompt lets you slide along a quality/cost frontier. In our paper benchmark with one specific lineup, Nemotron + Devstral as the two generators and GLM-5.1 as the judge, the adaptive router delivered ~56% cost reduction at matched quality, or ~7% quality bump at matched cost, vs the best fixed method we compared against at that same lineup. One knob (λ) does the sliding. The qualitative pattern (adaptive beats fixed) should generalize, but absolute numbers are lineup-specific, and we haven't run the full sweep across other model combinations yet. Adoption is change one import: python - from openai import OpenAI + from agentcodec.openai import OpenAI Pass reliability="harq_ir" (or any of the 28 techniques) and existing client.chat.completions.create(...) calls keep their native OpenAI response shape. Same drop-in shims for Anthropic and Ollama. GitHub: https://github.com/intellerce/agentcodec Working paper: https://arxiv.org/abs/2605.09121 After spending a while researching reliability methods from papers, we kept hitting the same wall: every paper ships its own one-off codebase with its own prompt format, its own scoring rubric, its own model wrapper. Benchmarking "should we use self-refine or best-of-N here?" turned into a week of plumbing per comparison. The communication-theory framing is what tied it together: an LLM is a stochastic channel Y = A(X) + N, and every reliability technique from the wireless world has a direct analog in agent-land: Wireless Agent-land ARQ / HARQ retry-with-feedback loops Diversity combining (MRC/SC/EGC) ensemble multiple models Turbo decoding iterative generator/critic mutual refinement Fountain codes rateless sampling, stop when the judge is confident FEC answer + structured parity passes (re-derivation, verification, alternative), decode by cross-check ACM (adaptive coding-modulation) route by difficulty We put all of them in one library: 28 reliability techniques (the 7 prior-method baselines are part of that 28, not on top of it), plus the uncoded single-pass baseline they're all measured against, plus 3 adaptive routers (SemKNN + two local ACM routers) that select a technique per prompt. Full breakdown in the README. The minimal version ```python from agentcodec import ReliabilityModule mod = ReliabilityModule.from_dict({ "models": [ # Spatial diversity: two different families = uncorrelated errors {"model": "qwen3:8b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, {"model": "llama3.1:8b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, ], "judge": {"model": "gemma3:12b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, "critic": {"same": True}, "strategy": {"type": "fixed", "technique": "harq_ir", "params": {"max_rounds": 4}}, }) result = mod.run("Prove the sum of the first n odd integers is n2.", category="reasoning") print(result.text, result.cost_usd, result.cost_source, result.technique_used) ``` Swap "harq_ir" for "diversity_mrc", "turbo", "fountain", etc. Same API, same ReliabilityResult shape, same cost-source tier on every output. For production, flip strategy to routed and the library picks the technique per prompt (cheap baseline on easy prompts, diversity_mrc on hard ones). Three things worth calling out Beyond the technique catalog, three pieces of the implementation that took real work: 1. Native async streaming for all but 2 techniques (acm_soft, acm_learned), with role-tagged events. mod.astream() drives AsyncOpenAI / AsyncAnthropic / httpx.AsyncClient end-to-end (no worker-thread bridge) and emits TokenEvents tagged with a role: "answer", "thinking", "draft", "critique", "verification", "candidate", "synthesis". So when you stream a HARQ-IR run, you can render the round-by-round drafts and critiques live, not just the final answer: python async for ev in mod.astream("Explain QUIC vs TCP."): if isinstance(ev, TokenEvent): if ev.role == "answer": print(ev.text, end="", flush=True) elif ev.role == "draft": print(f"\n[draft] {ev.text}") elif ev.role == "critique": print(f"\n[CRITIC] {ev.text}") elif ev.role == "thinking": pass # captured to result.thinking_text elif isinstance(ev, FinalEvent): print(f"\ndone — {ev.result.technique_used}, " f"thinking_cost=${ev.result.thinking_cost_usd:.4f}") Parallel-branch techniques fan out concurrently via asyncio.gather. diversity_mrc with two models actually runs them in parallel, and you see per-branch ProgressEvents as each one completes. 2. Thinking-text capture across all backends. Anthropic ThinkingBlock, OpenAI reasoning_content (+ exact reasoning_tokens from usage.completion_tokens_details), Ollama msg.thinking, and inline ... tag stripping (DeepSeek-R1, Qwen3, GLM-4.5+, Nemotron) all populate result.thinking_text and split result.cost_usd into thinking_cost_usd + answer_cost_usd. So you can finally see what the o-series / Claude / DeepSeek is actually charging you for. 3. Drop-in compat shims with expose_reliability_stream=True. Default: the shim looks identical to the native SDK, delta.content for the answer, delta.reasoning_content for thinking. Drafts/critiques are hidden so existing code keeps working unchanged. Set the flag and the shim surfaces internal roles via sentinel fields (delta.agentcodec_role, delta.agentcodec_call_id) that existing consumers ignore harmlessly: ```python from agentcodec.openai import AsyncOpenAI client = AsyncOpenAI(api_key=KEY, reliability="harq_ir", expose_reliability_stream=True) Now drafts/critiques flow through the native OpenAI stream with sentinels. ``` Same flag and same semantics on agentcodec.anthropic.AsyncAnthropic and agentcodec.ollama.AsyncClient. Other useful bits Cost transparency built in: every result carries a cost_source tier marking how the price was obtained, from exact_user_rate (you supplied the rate) through openrouter_rate / exact_table_rate / inferred_table_rate down to default_fallback, plus token-estimation flags when only character counts were available. Live pricing fetched from OpenRouter, cached locally for 7 days. No more "I think this run cost $40, maybe?" Works against whatever you have: OpenAI, Anthropic (native SDK), Ollama (native + python lib + OpenAI-compat), vLLM, OpenRouter, LM Studio, Together. No Docker, no separate inference server, no LangChain. Strict config schema: typos in YAML / dict configs raise at load time, not on first .run(). 195 tests, 25 runnable examples under examples/: async streaming, thinking capture, drop-in compat for all three backends, plus a fully-annotated YAML config. Caveats The headline numbers are for a specific model lineup. The ~56% cost / ~7% quality figures come from a single benchmark run with Nemotron + Devstral as the two generators and GLM-5.1 as the judge. We expect the qualitative pattern (adaptive routing dominates fixed) to hold for other model combinations, since that's the whole point of the framework, but the absolute numbers will move with the lineup, and we haven't done the cross-lineup sweep yet. If you swap in different generators expect different absolute savings; the right comparison is your adaptive vs your best fixed baseline at your lineup. License is PolyForm Noncommercial 1.0.0: free for research, teaching, personal/internal eval. Commercial use needs a separate license. The trained SemKNN routing artifacts (learned router mapping prompt embeddings → best technique, the thing that delivers the headline cost number) are not redistributed; the client talks to a remote SemKNN service. All other routers (fixed, acm_table, acm_linear) run fully locally, though the last one needs you to train it. 2 techniques (acm_soft, acm_learned) still fall back to sync dispatch in an executor on the async streaming path. They produce correct FinalEvents but no mid-stream tokens. Roadmap. This is research code. Expect rough edges on the less-traveled paths (soft-output diversity variants, the learned ACM router). Feel free to ask about specific techniques, the routing approach, how to add a new one, or the streaming / thinking / compat work. Suggestions on what to ship next are welcome. submitted by /u/Intellerce [link] [Kommentare]
As an ML researcher, how do you use AI tools in your daily work? Do you mostly use them to clean up grammar and wording, or also to rewrite, structure, or draft technical text? submitted by /u/Hope999991 [link] [Kommentare]