https://reddit.com/link/1u0rx4y/video/yhckg2drz56h1/player Sick of writing custom parsers every time I switch tactile sensors. Threw this together — one API, any sensor, 3 lines. Video shows the useful thing: demo: AI pre-annotate → review → export. Took me like 2 minutes. pip install tlabel import tlabel tlabel.demo() # try it right now, zero config Works with GelSight Mini, DIGIT, PaXini, Daimon. MIT, free. submitted by /u/ImmediateArm7942 [link] [Kommentare]
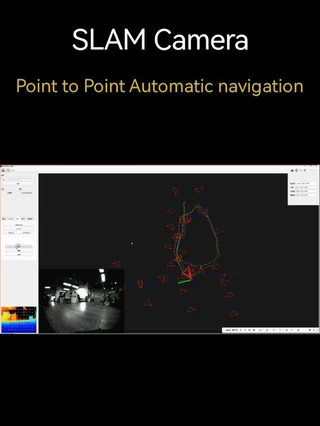
I've recently completed the assembly of a SunFounder PiCar-X and am currently running it on a legacy Raspberry Pi B. I have the base movement and motor control working and am currently prepping to get it chasing ArUco/AprilTags this coming week. I'm looking to evolve this platform into something capable of SLAM and eventually Structure from Motion (SfM). I'd love to get some community advice on the best way to handle these upgrades: Traction The stock wheels are quite slippery. Has anyone found direct-fit replacement tires or wheels that offer better grip on smooth indoor surfaces? Odometry Since the stock motors lack encoders, my dead reckoning is non-existent. Should I attempt to mount external encoders to these motors, or is it better to swap out the motor/gearbox assembly entirely for something with integrated feedback? IMU for SLAM I'm planning to add an accelerometer/gyroscope. Any specific sensors (such as the BNO055 vs. MPU6050) that are currently considered the "gold standard" for stability and ease of integration on a Raspberry Pi? Computer Vision The current camera resolution is limiting for SfM. Any recommendations for a higher-resolution CSI or USB camera that fits well within the PiCar's chassis? ROS 2 / Distributed Computing A specific question on the software side: I'm planning to move this platform to ROS 2. Given that I'm working with a legacy Raspberry Pi B, is this a lost cause, or should I keep the Pi as a low-level hardware node and offload the heavy ROS 2 processing, SLAM, and visualization tasks to a more powerful machine on my network? If a distributed setup is the preferred approach, what does the typical workflow look like? For example: Pi handles motor control, sensors, and camera acquisition ROS 2 nodes run on a desktop/laptop workstation Visualization and mapping performed via RViz on the workstation Communication over Wi-Fi using DDS Is this the recommended architecture, or are there better approaches for a platform like the PiCar-X? General Advice Any feedback on the hardware upgrade path, software architecture, or general "gotchas" with this kit would be greatly appreciated. Thanks in advance! submitted by /u/okineedaplan [link] [Kommentare]
hi everyone, I created a blog around how I started open source contribution, documented all minute details. Please give it a read and give review as this is my journey to do blogging for the first time. It is free! https://substack.com/home/post/p-200202050 submitted by /u/DqDPLC [link] [Kommentare]

This machine takes around four seconds for each solve. To reach that speed I had to use the kociemba algorithm, which can find a solution of around 20 moves for all scrambles. It took me a really long time to complete this so I would appreciate it if you show it some love! I made this when I was around 15. Please ask questions! submitted by /u/Henry517 [link] [Kommentare]
TL;DR struggling in finding a meaningful research contribution on top of existing big foundation models. (edit: please note it's my first post on reddit,I'm not a bot) Context: I'm working on FM applied to robotics: VLAs, world models, WAMs. Lately I'm mostly reading papers, and implementing small adds on. Those topic are really exiting but I’m wondering where modest researchers (like me) can make meaningful contributions, given that training competitive foundation models from scratch is a big-lab game. For people working on fondation models in academy and R&D, that asked themself similar questions: Do you have some honest suggestions or feedback? If starting from a pretrained fondation model, main things that come to my mind are eg: - architecture changes (don't you lose all the pre training warmup)? - fine tune (not much new science if one runs lora...) - froze the model and build add-on like uncertaintyquant , world-model lookahead, inference guidance, safety constraints - something big I'm not seeing? Also happy to hear paper/project recommendations that are good examples of this. Thank you all. submitted by /u/Amazing-Coat5160 [link] [Kommentare]
Yes, I'm calling it out. It IS racism. As an active member of r/MachineLearning and a researcher who is ethnic Chinese, I am DISGUSTED by unfounded accusations against the group of researchers who constitute over half of the field. Such posts pop up every other week, grounded in conspiracy theories, and creating a sinophobia echo chamber. I understand the salty feeling when one's paper is rejected, no matter whether the paper actually deserves acceptance or not. Given the noise in conference organization and reviewing process, and a relatively junior body of participants, it is very likely that one finds a paper "worse than mine" slip into the conference, and there's a high chance that the paper has a Chinese author. That's simply because of the composition of the authors, and does not warrant accusations, aka witch hunts, towards certain ethnic groups. This sub is about an important scientific subject in the modern world. If anyone agrees with the logic "80% of the authors are Chinese, so my rejection is their fault.", they should seriously rethink their career plan since such thinking does not belong to serious scientists. We should be open to discussing the problems we have in the current conference organization and reviewing process, but racism should not have a foothold in our field. submitted by /u/AffectionateLife5693 [link] [Kommentare]

Hi r/MachineLearning, Wanted to share something I'm excited about. I’ve been fascinated by AlphaEvolve and its results for more than a year now, but using open source frameworks seems overwhelming because of the high costs. I can’t really afford hundreds of Claude Opus calls every time I want to run it. I want to be able to try it out many times and all sorts of unique domains. What if it was possible for AlphaEvolve to be much more affordable while getting a better performance? Over the last six months or so, I’ve been working on LEVI, an open source AlphaEvolve-like system that can outperform existing open source frameworks at a fraction of the cost (upto 35x cheaper!). It can also run on Claude Code or Codex, making it even more accessible (I've mostly been using it with a QWEN-30B). LEVI comes in two flavors where I felt it’ll make the most difference: Code Optimization, and Prompt Optimization (sorry math, you got a less direct path; workable through the code route). The core thesis behind LEVI is that with the right search architecture, smaller models can substitute for or outperform larger ones. This means it’s much more economical to rely on smaller models for most of the work. That’s the entire takeaway. Making this work in practice is a different problem, but if you forget everything else from this post this is the only message I think I’m really trying to convey here. LEVI does it in three ways: 1) Invest in solution diversity from the start and ensure its maintained. We don’t want to converge to the same solution, especially with smaller models in the mix, and rely on large models to pull us out of the basin. 2) Use smarter routing across larger and smaller models (i.e. most mutations don’t require a Claude Opus X) 3) For prompt optimization not every rollout is as important. Build a proxy subset to approximate. I’ve tried LEVI on systems problems (like MoE scheduling or database transaction scheduling) and found that LEVI outperforms existing frameworks on almost every problem I threw at it while consistently using a smaller budget (unto 7x cheaper). For prompt optimization, across problems like IFBench and HotSpotQA, LEVI reaches a similar or better score as GEPA while using less than half the rollouts! Happy to answer any questions or take any suggestions! If there are unexpected or niche domains where this can be applied, I would love to hear. Technical Blog: https://ttanv.github.io/levi/ GitHub: https://github.com/ttanv/levi submitted by /u/Longjumping-Music638 [link] [Kommentare]
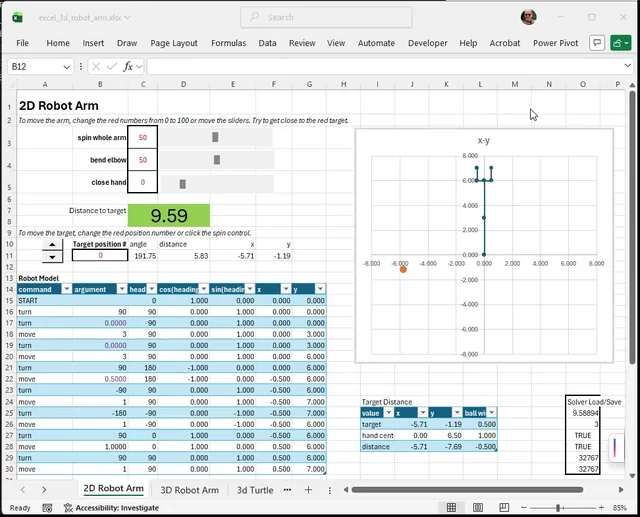
I made a playable Excel workbook that models a 2D and 3D robot arm using only ordinary spreadsheet formulas, charts, sliders, and Excel Solver. The idea is to make kinematics easier to understand. GitHub: https://github.com/CarlKCarlK/excel-3d-robot-arm The 3D arm is inspired by the old Radio Shack / TOMY Armatron toy robot arm. The workbook lets you move the arm manually, set a target point, and then use Excel's Solver to find the control settings that move the hand to the target (inverse kinematics!). I made this mostly as a learning project. Excel makes the math visible: the rotation matrices, position updates, target error, and Solver setup are all inspectable cell by cell. Nothing is hidden in a robotics library or graphics engine. The model itself is just a series of rows, each controlling one segment. The rows process 3 ways to turn (yaw, pitch, roll) or a move, turtle graphics-style. submitted by /u/carlk22 [link] [Kommentare]
I've been building agents for about a year and recently shipped one for a client running ~140 MCP-exposed tools at peak. Along the way I made the canonical mistake. I used cosine similarity over tool description embeddings to pick which tools the model could see per turn. Worked great in demos. Was actively dangerous in production. Here's the problem. In a basic semantic-ranking setup you embed the user query, embed every tool description once, and rank by cosine similarity at runtime. That works for general document retrieval where chunks are paragraph-length, semantically rich, and roughly equal in form. Tool descriptions are not that. They are short (often

Hey reddit, So we built a gaming accessibility app SensePilot that enable people with disabilities to control a computer and play video games. I just finished developing the human-robot interface prototype so thought I'll share the demo here too as its related to robotics. Hope to eventually apply this to assistive living robots, because their controls are usually very limited and their users are unable to use hands for controlling the robot very well. submitted by /u/SensePilot [link] [Kommentare]
I'm looking to buy a robot arm through AIFITLAB - has anyone done a major purchase through them recently? I'm looking to buy an AgileX NERO, price seems lower than US based companies which I know might be due to tariffs submitted by /u/Vassaci [link] [Kommentare]
hi,where can i find Maven AI Evals for Engineers & PMs and End-to-End AI Engineering Bootcamp videos.They are too costly.cant afford them.Can anybody help me in finding the resoursec for them? submitted by /u/Zestyclose_Block5381 [link] [Kommentare]

From C. Zhang on 𝕏: https://x.com/ChongZzZhang/status/2062837883178738107 Project: MotionDisco: Motion Discovery for Extreme Humanoid Loco-Manipulation Website: https://atarilab.github.io/motiondisco.io/ ArXiv: https://arxiv.org/pdf/2606.06139 submitted by /u/Nunki08 [link] [Kommentare]