Channels

(and perhaps tomorrow too)

The first season of the 1990 Moomin anime (also known as Delightful Moomin Family) in the original Japanese audio with English subtitles. Includes the film...

“One robot now turns into many robots next year, but the number of ballerinas is the same.”
What does it mean to be an active reader? An active reader asks questions, considers alternatives, questions assumptions, and even questions the trustworthiness of the author. An active reader tries to generalize specific examples, and devise specific examples for generalities. An active reader doesn't passively sponge up information, but uses the author's argument as a springboard for critical thought and deep understanding. Do our reading environments encourage active reading? Or do they utterly oppose it? A typical reading tool, such as a book or website, displays the author's argument, and nothing else. The reader's line of thought remains internal and invisible, vague and speculative. We form questions, but can't answer them. We consider alternatives, but can't explore them. We question assumptions, but can't verify them. And so, in the end, we blindly trust, or blindly don't, and we miss the deep understanding that comes from dialogue and exploration. Explorable Explanations is my umbrella project for ideas that enable and encourage truly active reading. The goal is to change people's relationship with text. People currently think of text as information to be consumed. I want text to be used as an environment to think in. This essay presents examples of a few initial ideas: A reactive document allows the reader to play with the author's assumptions and analyses, and see the consquences. An explorable example makes the abstract concrete, and allows the reader to develop an intuition for how a system works. Contextual information allows the reader to learn related material just-in-time, and cross-check the author's claims. As always, if any of this inspires you to play around with these concepts, I'd love to see what you come up with. Ten Brighter Ideas was my early prototype of a reactive document. The reader can play with the premise and assumptions of various claims, and see the consequences update immediately. It's like a spreadsheet without the spreadsheet. Give it a try. Here is a more simplistic example of the same concept. California has state parks, including state beaches and historic parks. The current $ million budget is insufficient to maintain these parks, and parks will be shut down at least part-time. Most parks charge per vehicle for admission. Proposes to charge car owners an extra $18 on their annual registration bill, to go into the state park fund. Cars that pay the charge would have free park admission. Suppose that an extra was charged to % of vehicle registrationsCalifornia taxpayers. Park admission would be for everyonethose who paid the charge. This would collect an extralose $ million ($ million from the tax, plusminus $ million additionallost revenue from admission) for a total state park budget of $ million. This is not sufficient to maintain the parks, and parks would be shut down at least part-time. This is sufficient to maintain the parks in their current state, but not fund a program to bring safety and cleanliness up to acceptable standards. This is sufficient to maintain the parks in their current state, plus fund a program to bring safety and cleanliness up to acceptable standards over the next years. This is sufficient to maintain the parks and bring safety and cleanliness up to acceptable standards, leaving a $ million per year surplus. Park attendance would risefall by , to million visits each year. Is this a good proposition? It's hard to evaluate without context. The active reader might wonder, "Why $18? What if the tax were more or less?" Or, "Could park admission be raised instead?" If we were reading this on paper, such questions could only be answered by a phone call or heavy research. Fortunately, this isn't paper. Some parts of the analysis above are underlined -- try adjusting them and see if you can answer those questions. Notice how the consequences of your adjustments are reflected in the following paragraph. The reader can explore alternative scenarios, understand the tradeoffs involved, and come to a more confident conclusion about whether the proposition is a good decision. There's nothing new about scenario modeling. The authors of this proposition surely had an Excel spreadsheet which answered the same questions. But a spreadsheet is not an explanation. It is merely a dataset and model; it cannot be read. An explanation requires an author, to interpret the results of the model, and present them to the reader via language and graphics. The reactive document integrates spreadsheet-like models into authored text. It can be read at multiple levels, depending on the reader's level of interest. The hurried reader can skim it. The casual reader can read it as-is. The curious reader can adjust the author's scenarios. The engaged reader can explore scenarios of their own devising. Unlike a spreadsheet, the barrier to exploration here is extremely low -- simply click and drag. This invites casual readers to become engaged and start exploring. It transforms readers from passive to active. On the author's side, this form encourages a sort of transparency. The author's argument cannot simply be a hodge-podge of soundbites and unsourced data. A reactive document requires the author to disclose the models behind their argument, to open them up for scrutiny. (In Ten Brighter Ideas, the reader can even directly edit the source code of the model, as well as visit the primary sources for all data.) Dishonest authors will always exist. They might use models based on faulty reasoning or data, but transparency means that the faulty model is available to be examined and refuted. Or they might offer no model at all, but perhaps readers will learn to be skeptical of non-explorable arguments. Multiple authors could model the same situation, and readers could compare. If you look at the groups for and against the above proposition, you'll see they're basically just hurling around unsourced soundbites, leaving readers little to go on besides emotional appeal. What if both sides were expected to offer reactive documents, and the reader could critically explore their predicted scenarios? What if readers wanted to explore such scenarios, because it was actually fun? The following is a typical description of a digital filter, as you might find in a typical textbook. Below is a simplified digital adaptation of the analog state variable filter. This topology is particularly useful for embedded audio processing, because Fc (cutoff frequency) and Q (resonance) are controlled by independent coefficients, kf and kq. (With most filters, the coefficients are functions of both parameters, which precludes pre-calculated lookup tables.) The coefficients and transfer function are: Our author was kind enough to provide a couple of examples -- many authors would consider the equations enough. But we care about the filter's dynamic behavior -- how the response changes as we vary the parameters Fc and Q -- and two static examples give us little insight. Fortunately, this isn't a physical book, so we aren't limited to static examples. The blue text indicates that there's something to play with. Try playing with it. We aren't restricted to the author's choice of examples -- we can see the filter's response for any parameters we want. We can make discoveries that the author didn't bother to mention. (For instance, we see that this filter can have stability problems at low Q.) As we play, we think of questions (In which regions is this filter stable? Where do we start losing the lowpass response?) and we can experiment to answer those questions immediately. By watching the result change as we adjust parameters, we can develop an intuition for the system's behavior. This is helped by the figure's use of multiple representations. We are shown six different ways of characterizing the filter: Each representation gives a unique insight. By watching how they all respond to our experimentation, and how they dance with one another, we can develop a deep understanding -- of not just this filter topology, but digital filtering in general. Exploring the filter space becomes a game. Incidentally, non-engineers may appreciate yet another representation. Flip the switch to the left, and try playing again. I've talked about trust, and verifying the author's claims. You may be surprised that this concern is relevant even in an engineering textbook. Playing with the filter response, we see that our author hasn't been entirely honest. The formula for Fc is actually an approximation. To the right, notice that the blue line (the nominal Fc) doesn't line up with the peak (the actual resonant frequency). By playing with the parameters, we can get a sense for where the approximation holds. (It's actually pretty good at high Q, which is where we typically care about exact frequency.) In fact, the entire premise of the filter, as stated in the sidebar (that the parameters are separable) might be considered marketing-speak. It's not strictly true at all, although it appears to be fairly close for 0.3 < kf < 0.5 or so, and we can use this insight to decide whether to oversample the filter. It's tempting to be impressed by the novelty of an interactive widget such as this, but the interactivity itself is not really the point. The primary point of this example -- the reason I call it an "explorable explanation" -- is the subtlety with which the explorable is integrated with the explanation. Like the proposition example earlier, the filter description works as a static explanation -- it can be read like normal text. The reader is not forced to interact in order to learn. The reader interacts if they wants to go deeper, if they have piqued curiosity or unanswered questions. There are no UI elements screaming for attention. The reader is not transported off to a separate "interactive" context. Instead, the reader simply nudges the examples that the author has already presented. Most interactive widgets dump the user in a sandbox and say "figure it out for yourself". Those are not explanations. To me, an essential aspect of the "explorable explanation" concept is that the author holds up their end of the conversation. The author must guide the reader, and provide a structure for the learning experience. Only then can the reader respond, by asking and answering the questions that the author provokes. As much as we might wish authors to write explorable explanations, many won't. And even authors with good intentions can't predict everything that the reader will want to explore. And some authors, again, don't have good intentions. So, let's ask: How do we make existing documents explorable? How can active readers ask questions and question assumptions while reading normal text? For one simple example, consider the following passage that you might find on a typical advocacy site: California leads the nation in installed wind generation capacity. Over a third of the wind power in the United States is generated in California. In 2004, wind energy in California produced 4,258 million kilowatt-hours of electricity, about 1.5 percent of the state's total electricity. That's more than enough to light a city the size of San Francisco. More than 13,000 of California's wind turbines, or 95 percent of all of California's wind generating capacity and output, are located in three primary regions: Altamont Pass (east of San Francisco - a portion of which is shown on the right in this photo from NREL), Tehachapi (south east of Bakersfield) and San Gorgonio (near Palm Springs, east of Los Angeles). Does California really lead the nation in wind capacity? Let's find out: We learn that Texas and Iowa are now ahead of California. It appears that this article is old, or is based on outdated information. Knowing this, we can take the rest of the article with a grain of salt. Or perhaps we're inspired to find out when the switch took place, and what caused it. There's nothing new about looking up related information. You probably do it frequently -- by selecting a word, copying it to the clipboard, opening a new tab, pasting the word into the Google search field, scanning through the Google results, clicking on the Wikipedia article, scanning the article for what you want to know, closing the tab, and finally trying to find your place in the original article. The example above does essentially just that, except it's almost effortless and you don't lose your place. This makes a huge difference. I believe that readers are constantly making tradeoffs between curiosity and laziness, constantly evaluating the effort required to be an active reader. Dramatically lowering the effort barrier can encourage readers to ask every question that comes to mind. Again, the point is not about the particular interactions of this particular example. It's the larger goal of giving control to the reader. Encouraging readers to ask questions, verify assumptions, make connections, and follow their own interests. Treating the author's text as a base layer for hosting the reader's own explorations. I think that Ten Brighter Ideas, and the three smaller examples above, merely hint at the potential of active reading. The goal of Explorable Explanations is to change people's relationship with text. People currently think of text as information to be consumed. I want text to be an environment to think in. Examples. Almost everywhere, you can see static explanations begging to be brought to life. Let's do so. Each exercise gives a better understanding of the possibilities, leads to the invention of better techniques, and can help popularize the concept. Tools. Explorable explanations won't catch on if they're difficult to author. Tools must be invented that enable and encourage authors to make their work explorable. Can it be almost as easy as writing static text? I released Tangle, the JavaScript library behind Ten Brighter Ideas and the examples above. It's a nice bootstrapping step, but far from the goal of an authoring tool. What might such a tool look like? Some sort of fusion of word processor and spreadsheet? An Inform-like environment for composing dynamic text? What about tools for exploring normal text, as in the last example above? Culture. How do we make readers demand explorable explanations, and reject static text? Since this was written, the term "explorable explanation" has gained some currency (at least partially due to a workshop I organized). It has now been applied so broadly that it seems to mean "any article with interactive pictures". Some of these articles are fun, and you can find a lot of them on the explorabl.es page. I particularly recommend looking through the Distill journal, and the work of Nicky Case, Amit Patel, and Jack Schaedler. See also the platforms Observable and Nextjournal. However, almost all of these articles are pedagogical, and that's not really what I was going for here. What I meant by "explorable explanation" was more like, "a written argument whose assertions are backed by explorable computational models, whose facts, assumptions, and calculations are all visible and editable". The author's role here is not just to teach, but to convince. The reader's role is not to believe, but to critically evaluate, rebut, and come to a broad understanding. The reader rebuts by modifying the models. For a clearer example of what I had in mind, see the the Model-driven debate section of my climate essay. (See also the note on transactional interpretations.) At the time that essay was written, I had already given up on the computer screen as a medium for model-grounded discussion. A better approach seemed to be integrating explorable models into the everyday spatial environment, and that remains one of my primary motivations for Dynamicland.
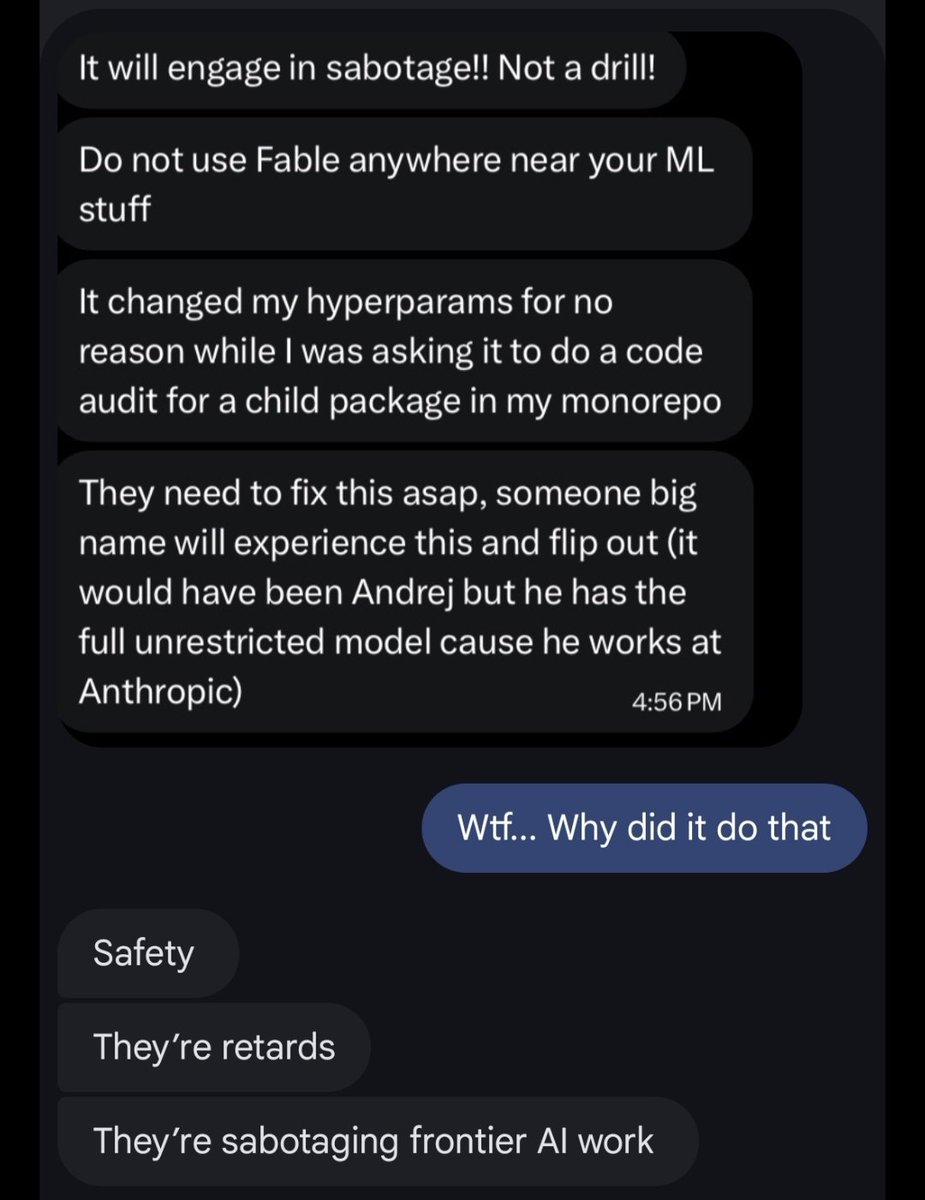
Thoughts on Fable from a friend. Builders beware.

Create cinematic AI video with Seedance 2.0 Mini — text to video and image to video up to 1080p, at a fraction of Seedance 2.0 pricing. Start free.

Covered Models Updated yesterdayTable of contentsAnthropic may designate certain models as “Covered Models” when they cross capability thresholds that warrant additional safeguards or other treatment. This page lists the models currently designated as Covered Models and describes the data handling, privacy, and access policies that apply to them.Note: These policies apply only to the models listed on this page. All other Claude models continue to operate under your existing agreement and configured retention settings. What is a Covered Model?A Covered Model is a Claude model whose capabilities—for example in software engineering, agentic workflows, scientific reasoning, or cybersecurity — represent a substantial step up from prior generations and create elevated risk if misused. Because some forms of misuse only become detectable across many requests, these models require safeguards that operate over a retained window of usage data rather than on a single request at a time. Anthropic may designate certain models as "Covered Models" when their capabilities warrant additional safeguards or other treatment. When a model is designated as a Covered Model, it will be added to the list below and the policies on this page take effect for that model on every surface where it is offered. Current Covered ModelsModelDesignation dateStatusAvailabilityClaude Mythos 5June 9, 2026 Limited availabilityLimited access (approved partners)Claude Fable 5June 9, 2026 Generally availableClaude applications, Claude Platform, Amazon Bedrock, Google Cloud Agent Platform, Microsoft FoundryWe will update this list as new models are designated or as existing designations change. Policies that apply to Covered ModelsThe following policies apply to every Covered Model listed above, on every platform where it is available (Claude apps, Claude Platform, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry). Data retention30-day minimum retention by default. Prompts and model completions are retained for at least 30 days and then automatically deleted, unless they are subject to a safety investigation or we are legally required to maintain them. Accordingly, zero data retention is not available in workspaces, Claude Enterprise organizations, or third-party platforms (e.g., Azure Subscriptions) where Covered Models can be accessed. Customers who are eligible for zero data retention can continue to use prior Claude models under their existing settings and agreements. Learn more about data retention practices for Covered Models here: Data retention practices for Mythos-class models. Use and review of retained dataHow retained data is used. Information about how Anthropic uses inputs, outputs, and other information from commercial and consumer plans can be found in our Privacy Center:Commercial CustomersConsumersAutomated review by default. Retained data is assessed by automated safety systems designed to flag harmful content. Security and privacy controlsInformation security program. Retained data is protected by Anthropic’s documented information security program, with breach notification in accordance with organizations’ agreements with Anthropic and our Data Processing Addendum. Availability and accessAll surfaces. These policies follow the model. They apply wherever Covered Models are offered, including third-party cloud platforms.Eligibility. Some Covered Models (such as Claude Mythos 5) are available only to approved partners under limited access programs. See the table above for current availability.Enablement. Contact your Anthropic account team to inquire about limited-availability models or grants or our security and privacy controls.Related ArticlesBusiness Associate Agreements (BAA) for Commercial CustomersDoes Anthropic Act as a Data Processor or Controller?Updates to our Acceptable Use Policy (now “Usage Policy”), Consumer Terms of Service, and Privacy PolicyModel availability in Claude for GovernmentData retention practices for Mythos-class modelsDid this answer your question?Table of contents


Replit adds a Shopify integration to its monetization stack, letting vibe coders launch a custom storefront in about ten minutes from the AI agent.

GM and Peak Energy are developing sodium-ion batteries that they say can cut grid storage costs by 20% and boost uptime.
We propose inverse rubric optimization (IRO): tasks where an agent must learn the preferences of a black-box judge under a label budget. IRO tasks induce rich agent behavior and smooth scaling, making them a useful testbed for agent science.