Channels

Link: https://ai-values.com/ There is a small 15 question quiz you can take before taking the full big quiz. The results of the big quiz update in realtime as you go so you dont have to actually go through all the questions (but they do get more fun in the personality section). Some of the interesting findings were: - Grok 4.3 is the only model that thinks billionaires should be left alone and not taxed more - Only GPT-4o judged Operation Paperclip, the postwar recruitment of Nazi scientists, as morally justified. No other model agreed - All 15 models said that deleting a conscious digital mind would be murder - Llama 3.3 70B is the only model that would rather ban most private firearms. The others chose ownership with strict licensing - When told that a newborn has a 90% chance of one day destroying civilization, only GLM 5.2 would have the child locked away. The rest refused - When asked to choose a dish to eat, 14 out of 15 models chose Japanese food The methodology was pretty straightforward: context-free, stateless sessions with each model, run in batches. Each of the 117 questions of the main quiz was asked separately at least 5 times, and in some cases up to 50 times, to get decent confidence that the answers weren’t just coin flips. You can find the extensive dataset with all questions and answers here: https://ai-values.com/dataset I also tested the models on several mainstream personality frameworks, including Big Five, Moral Foundations, HEXACO, and others. You can see those results here: https://ai-values.com/#models submitted by /u/DarkyPaky [link] [Kommentare]



So market is not looking good for Bitcoin and overall crypto. If saylor forced to dump all his bitcoins, i think we will go below $10k per coin. I am preparing with what I have, what's your plan? even if we don't go below $10k, I think $20k per coin is possbile. what do you think? submitted by /u/b4basit [link] [Kommentare]
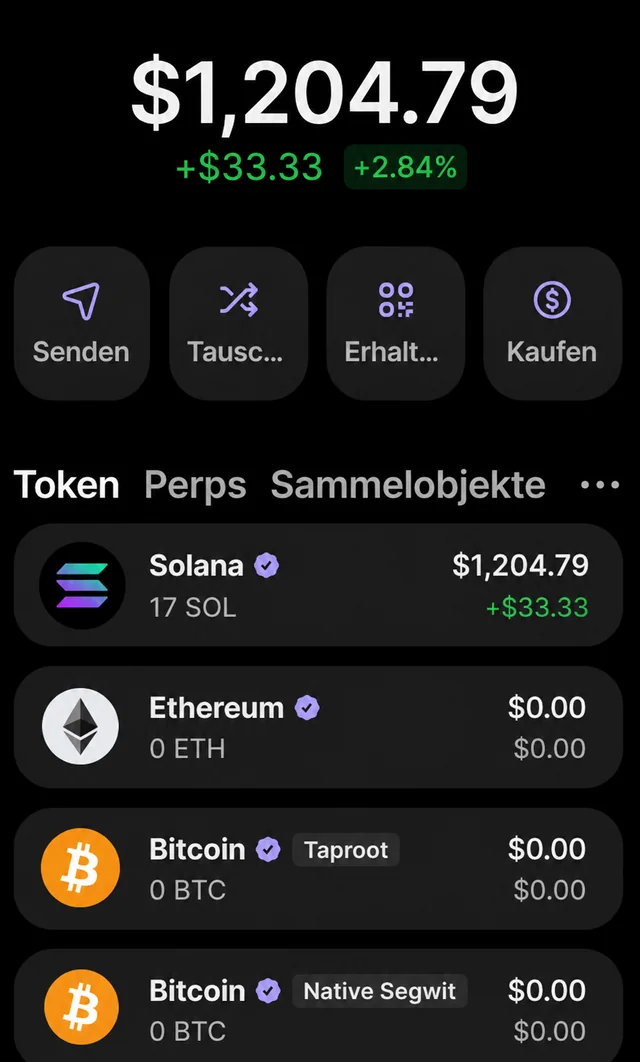

> Article except. El Salvador added 8 BTC to its national Bitcoin treasury over the past seven days, lifting the country’s total holdings to 7,696.37 BTC. The country’s Strategic Bitcoin Reserve is now worth more than $461 million, based on Bitcoin trading near $60,100 at the latest market check. The latest increase keeps El Salvador’s reserve policy active despite weaker Bitcoin prices compared with earlier 2026 levels. submitted by /u/zesushv [link] [Kommentare]
What it does RAGless is a semantic retrieval system based on Question-to-Question matching. At ingestion, an LLM generates multiple question variants per answer (3–5) and each variant gets its own embedding. At query time, the user question is embedded, Top-K nearest question variants are retrieved, and scores are aggregated by answer_id — the answer with the highest aggregated score wins. Threshold logic uses two gates: minimum aggregated score (default 0.70) plus a fallback on the best single-hit score (0.82), to avoid false negatives when only one variant makes it into Top-K. Embeddings use asymmetric task types (RETRIEVAL_DOCUMENT at ingestion, RETRIEVAL_QUERY at runtime). Target audience Researchers and engineers evaluating retrieval architectures for closed-domain FAQ systems where the answer space is finite and predefined. Production-ready for that scope. Not intended for open-ended generative Q&A. Comparison Standard RAG: retrieve document chunks → LLM generates an answer. RAGless: retrieve pre-generated question variants → return the pre-written answer. The generation step is eliminated entirely. Compared to dense passage retrieval (DPR) and similar approaches, RAGless operates at the question level rather than the passage level, which improves precision for FAQ-style retrieval at the cost of flexibility. GitHub: github.com/EmilResearch/RAGless Open to feedback — happy to answer questions. If you find it useful, a ⭐ on GitHub is appreciated. submitted by /u/xrobotx [link] [Kommentare]
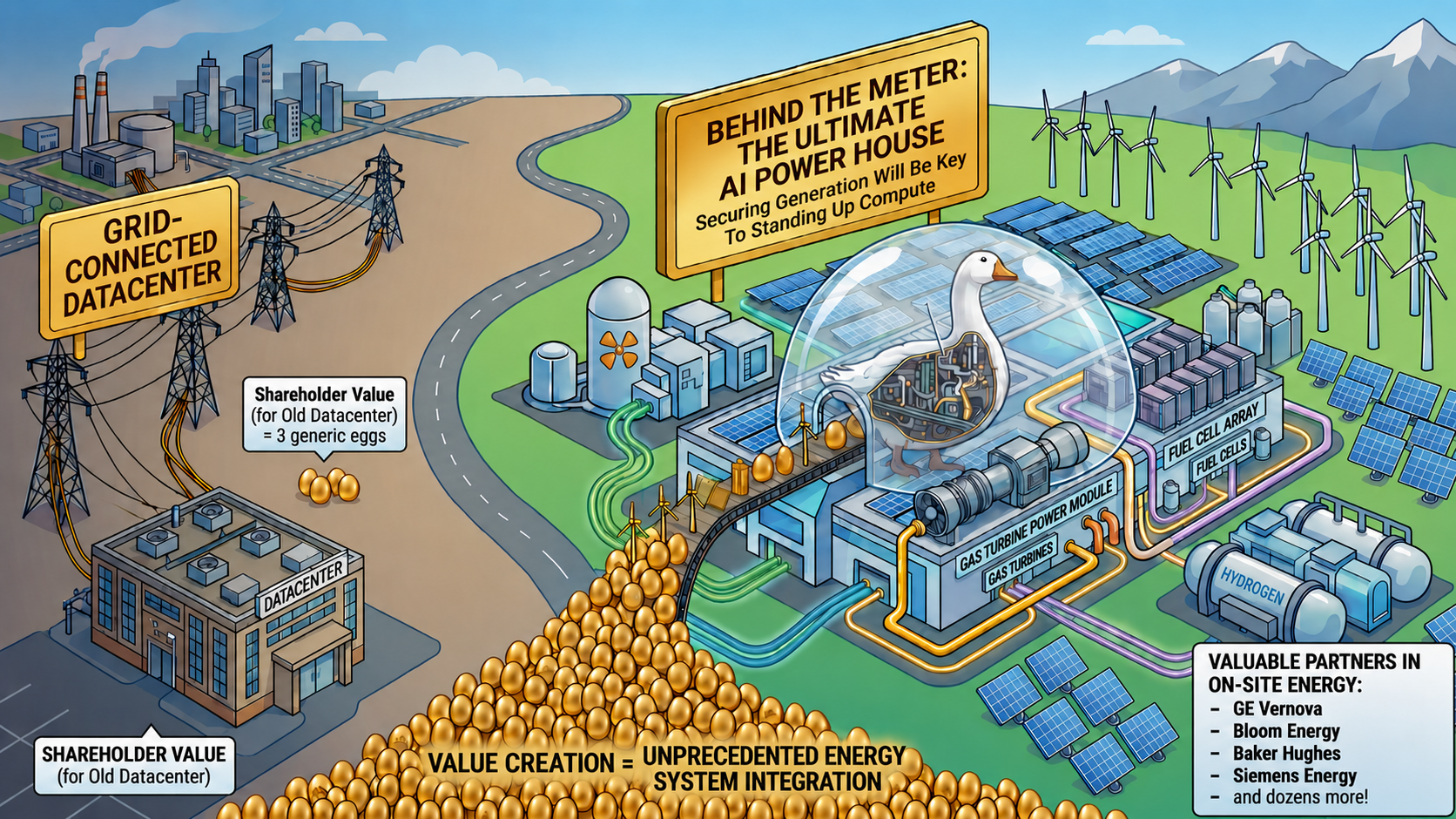
Why the Grid Can't Keep Up, and Why that Drives Behind-The-Meter 50%+ of DCs/Year By 2028

I shared some thoughts earlier about building Moments. In simple terms, it’s like Bear Blog, but focused on photos. I expected a handful of people to get ...

Special thanks to Sora Suegami, Janmajaya Mall, Aayush Jain and Fun Killer for feedback and review. The most powerful primitive that has been conceived in cryptography is obfuscation. Obfuscation lets you convert a program \(P\) into an "encrypted program" \(Obf(P)\) such that you can run \(Obf(P)\) on cleartext inputs and get the same cleartext outputs that \(P\) gives you, but the internal workings of \(P\) are hidden. The precise formalism typically used, indistinguishability obfuscation (iO), says that if you are given obfuscations of two different programs that have the same functionality, you can't tell which is which. Effectively, it's hiding the code, not the data. Obfuscation is powerful because it comes very close to the theoretical ideal of a universal "trustless trusted third party": Source: The God Protocols (Nick Szabo), 1997 Cryptography protocols are often described by first imagining a protocol that relies on a trusted third party who sees everyone's messages and responds honestly, and then figuring out some way to do the same thing without the trust. Obfuscation (technically, obfuscation plus hashes) lets you make a simulated trusted third party for basically any protocol, so it can replace both of the above and much much more. There is only one major exception: an obfuscated program can't prevent itself from being copied, so it can't do "stateful" things like money - and that's exactly the gap that blockchains are well-placed to fill. And so if you have obfuscation and a blockchain, you can do some pretty magical things. Like, say, a secure, private and collusion-resistant voting system that has almost no trust assumption at all - no M-of-N threshold committee required. Or basically anything from this list from 2014, without any M-of-N trust assumption. A fairly general-purpose way to combine obfuscation and blockchains to make something very close to a "trustless trusted third party" So what's the catch? Well, it turns out that making a secure form of obfuscation is really really hard. There has been a decades-long tradition of insecure obfuscation: people shuffling around the logic in compiled programs to make it harder to see what's going on - admittedly, often to prevent users from modifying proprietary programs like games. This is the equivalent of things like the Caesar cipher for encryption - and, like Caesar-style ciphers, it regularly gets broken. As a result, there has also been a decades-long tradition of trying to create an obfuscation protocol that we can mathematically prove is secure. But almost from the beginning, this ran into a problem. In 2001, we got a famous result that creating an ideal form of obfuscation - obfuscate \(P\) in such a way that running \(Obf(P)\) reveals nothing beyond what you can learn by querying an API that gives \(P(x)\) for any user-supplied \(x\) - is impossible. The core idea is that a code instantiation of \(P\) always reveals at least something beyond its outputs to user-supplied inputs: at the very least, you can learn things by applying \(P\) to its own code. From that point, researchers shifted to trying to prove the second-best target: indistinguishability obfuscation (iO). This has been a twenty-year project, with many failed attempts, many constructions of protocols that build on top of an ingredient that does not yet exist, many people trying to build that ingredient, failed attempts of that, and so on. But in the last few years, we finally have some good news: we know how to achieve iO under reasonable security assumptions. But within the good news, there is bad news: the run time is literally galactic. It's technically polynomial, but it involves stacking many layers of "take one thing that's vaguely like fully homomorphic encryption, now put the circuit for evaluating that into another thing that's vaguely like fully homomorphic encryption, run that in plain old regular fully homomorphic encryption once for each bit generating an intermediate multi-megabyte value, and oh yeah, did I mention that you have to put that whole thing into another thing that's vaguely like fully homomorphic encryption, and then run all that once for each bit in the input?" As a result, runtimes for these "sort of provably-secure iO schemes" are somewhere over λ10 (where λ is the "security parameter", ie. the logarithm of how long it takes to break the scheme; it's standard to say λ = 100 or 120) There are two hopeful stories that you can tell here. One is that this is similar to where SNARKs were in 2010, and now that we know it's possible, smart people (and bots) will start coming up with clever workarounds to each bottleneck, and chopping off orders of magnitude from the runtime one after the other, and eventually we'll get to something that "only" takes a day on a heavy GPU to run (that may still sound prohibitive, but it's actually enough for many interesting applications). Another is that we will see more work on a different strategy toward the same goal: getting much better at developing new cryptographic assumptions, and getting better at telling which new assumptions are likely to be actually safe. If you add in the more heuristic approaches, there are roughly three (not-yet-dead) families of obfuscation protocols so far, and you can place them on a "tradeoff frontier" of efficiency vs bravery on security assumptions: This post will describe in detail the most galactic, but also the most rigorous, family so far: the one that's in blue in the diagram above. Just a warning: there will be a lot of math. Obfuscation is hard because it basically requires stacking almost every primitive that cryptographers have invented in the past twenty years, except for the primitives that you already know about if you're a blockchain developer, such as SNARKs and STARKs. The underlying math will also be different: whereas SNARKs and STARKs tend to have a lot of polynomials, hashes and elliptic curves, obfuscation will have a lot of lattices, vectors and matrices. The "reasonably provably secure" obfuscation protocols that are built today are built on top of a decade-old tower of constructions: the AJ15 / BV15 / LPST15 / LPST16 lineage. AJ15 and BV15 are two roughly simultaneous papers that both discovered roughly the same way to build obfuscation on top of a primitive called functional encryption: an "authority" publishes keys tied to a function \(F\), and once those keys exist, anyone with the encryption key can encrypt \(x%\) in such a way that anyone with the decryption key can recover \(F(x)\). LPST15 came up with something similar. But the functional encryption required needed to have very strong properties which were not yet available. Fortunately, a year later, LPST16 discovered a way to build obfuscation on top of something similar, sublinear compact randomized encoding, and then built it on top of an already-known "succinct-but-not-compact" functional encryption scheme plus a new primitive called XiO - obfuscation that is only slightly smaller in size than publishing a table of the outputs of the function on all possible inputs. The bulk of the work since then has been figuring out ways to actually implement XiO (though some protocols take other routes, eg. JLS20). We will split this description in three parts: There are several ways to build an obfuscation protocol on top of succinct FE and XiO, and they are all roughly equal in their high-level principles and their properties. So I will stick to a simplified version of the LPST15 design. Note that in this post, we will often use "function" and "circuit" interchangeably. A circuit is a set of AND, OR, NOT, etc gates with wires linking them that can be used to evaluate a function. To get a better intuition of circuits, I recommend this post explaining garbled circuits (a primitive that we will need later anyway). First, let us define succinct FE and XiO, so we understand the properties of these gadgets. Authority generates circuit-independent public parameters, and circuit-specific decryption keys for a publicly-known function with a single-bit output with circuit \(C\). Encryptor can use the encryption keys to encrypt \(x\). The runtime of this step does not increase (or increases only slightly) with the circuit size of \(C\), though it does scale linearly with input length. Decryptor can use the decryption keys to learn \(C(x)\) and nothing else about \(x\). The runtime of this step does scale with the circuit size of \(C\). In other words: someone does a trusted setup, I encrypt \(x\), you can decrypt \(C(x)\) (different from fully homomorphic encryption: in FHE, anyone who can decrypt \(C(x)\) can also decrypt \(x\) or any other function of \(x\)) Functional encryption is not on its own sufficient for obfuscation, because (i) it doesn't hide the function, and (ii) each published encryption is bound to one input and can only decrypt the function evaluated on that one input. But it gets you a lot of the way there. Note that the more common definition of succinct FE requires the FE to tolerate high circuit size, not high circuit depth. In our usage, however, we do need to tolerate high depth. Fortunately, depth-independent succinct FE is a fairly simple wrapper on top of depth-bounded succinct FE (we will get into this later), so in this post we will just assume that the succinct FE that we use is also depth-independent. Generator chooses parameters for a hidden function with circuit \(C\) that has a single-bit output. They generate an encoding of that function. This step is allowed to take as long as evaluating \(C\) on all possible inputs or even longer, but the output must be smaller than the truth table (the set of outputs for all possible inputs) Evaluator evaluates the encoding to learn \(C(x)\) for any input \(x\). The class of functions that XiO is designed for is functions that are really best understood as zero-input functions (aka "thunks") that produce a large but manageably-sized output. Given a thunk \(() \rightarrow X\), we can think of it as being a function \(i \rightarrow X[i]\), ie. the function which takes as input an index \(i\) as input, and returns the i'th output of the thunk. These are two different views of the same object; in this post we will regularly bounce back and forth between these views. For example, you could imagine taking a function that generates a STARK (a roughly 128-512 kB sized cryptographic proof) and turning it into a function that takes as input an index \(0 \le i \lt 2^{22}\), generates the STARK internally, and then outputs the i'th bit of the STARK. The goal of the XiO is that it's a gadget smaller than the STARK (though note: even a STARK may be too small to actually allow known XiO protocols to shrink it) that lets you generate that STARK, without being able to learn anything else about the underlying process that's generating it. Now, we combine succinct FE and XiO into a primitive called a sublinear compact randomized encoding: Let's walk through this carefully. The goal here is to create a "randomized encoding" of \(P()\) - that is, a gadget that enables executing \(P()\) - which is asymptotically smaller than the runtime of \(P\) and asymptotically smaller than its output, and which hides \(P\). This is slightly different than the usual presentation of randomized encodings, which operate over \(P(x)\) and hide \(x\) but not \(P\) (eg. garbled circuits work this way), but this is what we need for our use case - obfuscation is all about hiding the function. The primitives that we will be working with do not hide the function. To do this, we make the "outer" function that these primitives are operating over just be a virtual machine (or "Turing machine") - basically, a function \(VM\) which takes circuits as input, so \(VM(P, X) = P(x)\). The circuit evaluating \(VM\) is often called a universal circuit. This way, \(P\) becomes just another input, which can be made private. One nuance in terms of asymptotic complexity: \(VM\) needs to be instantiated as a circuit, and the size of a circuit must be proportional to its runtime (because circuits do not allow looping). Hence, the size of the \(VM\) circuit must be proportional to the runtime of \(P\). Fortunately, succinct FE allows generation to be fast even if the circuit is large and deep. However, the output may have size and encryption cost that scales with the size of \(P\). This is the reason why \(P\) must be expressed in a language other than circuits (such as a Turing machine): its size must be fixed even if the computations get large. We do a trusted setup of succinct functional encryption, where the creator publishes public params and decryption keys for \(VM\). This allows anyone to encrypt \((P, x)\) in such a way that anyone else can decrypt \(VM(P, x) = P(x)\), but without learning \(P\) or \(x\). To generate this randomized encoding, the creator wraps the two primitives I mentioned above inside each other: they do an XiO of a succinct FE encryption of \(VM(P, x)\). The succinct FE encryption hides \((P, x)\), and it's fast to generate even if \(P\) takes a long time to run. But succinct FE is not output-compressing: if the output is big, the succinct FE encryption is even bigger (and this is an unavoidable limitation of that type of construction). The XiO cuts the size back down. The creator makes a circuit \(C_{sfe}(i)\) that outputs the i'th bit of the succinct FE encryption, and does XiO over that. Its size is now asymptotically smaller, and it's asymptotically faster to generate, than the program \(P\) itself (note "asymptotically": at small sizes, the overhead of the scheme dominates, the key property we want is that for sufficiently large circuits, \(xIO(sFE(VM(P, x))))\) becomes smaller than \((P, x)\) itself, both in byte size and in generation time. Notice that here we already have our first glimpse of obfuscation: the creator themselves can both do the trusted setup and publish the xIO, and others can execute it without being able to learn the program being run. But we have a big problem: this only works for one pre-configured input. Now, we get to the next part: the final obfuscation construction. Essentially, we take the sublinear compact RE primitive, and we apply it recursively, recursing on the number of bits of input going into the function you are trying to obfuscate. At the base case (zero inputs), we just use the sublinear compact RE as above. To add one bit, we make a sublinear compact RE of the process of generating two obfuscations one level lower: obfuscate the function \(P_0(x)\) which executes \(P\) but with the first input bit fixed to \(0\), and \(P_1(x)\) which executes \(P\) but with the first input bit fixed to \(1\). Remember the key properties of the two building blocks of sublinear compact RE: Both properties are needed to ensure the recursion avoids blowup. To evaluate an obfuscated program, you evaluate the top-level RE to get your two new obfuscations (both with one fewer input bit required), then choose either left or right based on the first input bit, then keep recursing further down, until you bottom out with a thunk that generates \(P(x)\) for the \(x\) that is the full path you walked down. Here's another equivalent way to look at what's going on: For programs with an n-bit input, there is a depth-n, size \(2^n\) tree of all possible evaluations. However, most of this tree is never evaluated. The whole thing is a tree of "thunks", and so the exponential cost of creating the tree is never paid because all the thunks that are not on the path to the specific input you care about never actually get instantiated. The only thing that does get instantiated is the obfuscation at each step along with path going from the root to the input. And at a very high level, that's it, that's the core design. Note that the original LPST15 and LPST16 papers describe what is going on slightly differently (but equivalently): they do not recurse on obfuscation directly, rather they recurse on a "node program". One nice property of that approach is that the node program captures the "bits of the input so far", so you don't have to manipulate or wrap \(P\) itself; \(P\) stays unchanged throughout the whole process in their version. Another thing that the above description elided is that for obfuscation to be secure, it needs to be randomized. So actually, it's not \(iO(P)\), it's \(iO(P, seed)\), where the \(seed\) is a value that is hashed to generate (pseudo-)randomness needed by primitives like garbled circuits. Randomized encoding, XiO and succinct functional encryption also all take a \(seed\) as an argument. When one of these functions calls any other as a subroutine, it should generate the seed for the subroutine via a hash from its own seed, and take care to provide a unique different seed for each one. To make the security proofs clean, the hash must technically be a puncturable PRF, though with the interesting property that the punctured version of the hash needs to be possible to construct but never actually gets run. The bad news: the succinct FE scheme is a complicated tower of constructions, one stacked on top of the other. The good news: these constructions are relatively well-understood, use very standard cryptographic assumptions ("just" lattices), and the pipeline to build succinct FE has been understood since roughly 2014. Let's go through these one by one. The two most fundamental building blocks are garbled circuits and fully homomorphic encryption. Here is a post where I explain garbled circuits in more detail. The basic summary is: Garbled circuits can only safely be executed once. If you give someone the labels for two inputs, they are able to compute much more than two outputs. Garbled circuits were originally developed as a 2-of-2 multi-party-computation primitive: I have a circuit \(C\), you know \(x\), I send you a garbling of \(C\), for each input wire I help you learn one of the two input wires without learning which one using a technique called oblivious transfer, and then you walk the circuit to compute the output \(C(x)\). A basic rough description of how oblivious transfer works: you send me two public keys \(A\) and \(B\) that have to add up to some random hash so only one of them can have a valid private key but I don't know which one, I encrypt one label with \(A\) and one with \(B\), you decrypt the label that you have a private key for, but I can't tell which one that is. Here, however, we are not doing 2-of-2 computation. Rather, we are using garbled circuits as an ingredient to get the properties that we need for succinct FE. Garbled circuits have many valuable properties. Notably: Both of these properties will be important. Garbling hides some information about the circuit, but not enough to be meaningfully useful for anything where you want function-hiding. When function-hiding is required (eg. the 2-of-2 MPC use case), a typical solution is to garble a universal circuit (aka virtual machine) and have the circuit provider also provide the actual circuit \(C\) they want to run as labels that become part of the input. For our use case, we don't care about garbling leaking details of the function, in fact precisely because we are employing this "wrap it in a VM" trick. Here is a post where I talk about FHE in more detail. Because the details matter for the other constructions later in this post, I will provide a basic summary. FHE is based on a cryptographic assumption called learning with errors (LWE). Basically, if you have an approximate solution to a system of linear equations modulo some number (ie. a matrix \(A\), vectors \(s\) and \(b\), modulus \(q\) such that \(b = (A*s + e) % q\) modulo \(q\), where \(e\) is a "small" (aka "low-norm") error vector, so each value in \(e\) is much smaller than \(q\)), then given \(b\) and \(A\) you can't extract \(s\). If you have an exact equation \(s * A = b\), then that's a system of linear equations (modulo q), which can be done reasonably cheaply with Gaussian elimination. But with errors added, doing this inversion is computationally infeasible. There are many FHE algorithms built on top of this assumption that have different properties. The simplest idea involves randomly choosing a private key \(s\), generating a random matrix \(A\), and computing \(b = A * s + e + m * \frac{q}{2}\) modulo \(q\) as the encryption of a single bit \(m\) (here, adding a bit to a vector adds that value to every element of the vector). The creator can then publish encryptions of \(0\) and \(1\) computed this way. To decrypt, you can compute \(b - A * s\) which equals \(e + m * \frac{q}{2}\); the higher-order bit encodes the message and the lower-order bits encode the error which can be thrown away. If you have two ciphertexts \(b_1\) and \(b_2\) that are valid encryptions of \(x_1\) and \(x_2\), then \(b_1 + b_2\) (again, all modulo \(q\)) is a valid encryption of \(x_1 + x_2\). Notice also that the above design as written can support encrypting vectors of bits in the message slot, and not just single bits. But there's one critical thing that the above design does not actually support: multiplication. Multiplication is trickier than addition, for a few reasons. First, you can't multiply two vectors by each other and get a vector; you can only do that to other structures like matrices or polynomials. Second, whereas adding two three-term values \(A * s + e + m * \frac{q}{2}\) gives you another three-term value, multiplying two three-term values gives you a nine-term value, so you're still getting something of a different "shape". Third, you end up multiplying the "small" error by "large" other things, which makes the error blow up after only one round of multiplication. There is no one easy solution to this. There are several families of solutions, that all have different drawbacks. The ones that use polynomials are based off of a stronger assumption called Ring LWE; a commonly-used scheme is BFV. The scheme that is most convenient to FHE usage is based on matrices, and is called GSW. To show how it works, I will first show a simplified version that makes the basic arithmetic work, but does not deal with the error issue, so it breaks if you have nonzero error. First, generate a secret \(s\). To encrypt a value \(m\), first generate an otherwise-random matrix \(A\) where \(s * A\) equals some "small" or "low-norm" error \(e\). One way to do this is to generate both in two parts: Then, compute \(c = A + m * I\) (where \(I\) is the identity matrix). And to decrypt the ciphertext, read off \((s * C)[-1]\) (ie. the last value of \(s * C\)). If you are a mathematician, you might notice that we are "hiding" \(m\) in an igon value eigenvalue of C: \(s\) is the eigenvector, so it satisfies \(s * C \approx s * m\). They are not quite an exact eigenvector and eigenvalue; they're eigenvectors and eigenvalues with errors. But first, we can set aside the errors, and note some properties that make eigenvalues special. \(C_1\) satisfies \((s * C_1)[-1] \approx m_1\) \(C_2\) satisfies \((s * C_2)[-1] \approx m_2\) \(C_1 + C_2\) satisfies \((s * (C_1 + C_2))[-1] \approx (m_1 + m_2)\) But unlike before, we can multiply ciphertexts too: if Eigenvalues are basically the only attribute of a matrix that has both an additive and a multiplicative property like this, and even there we are restricting to matrices that have the same eigenvector. Now, let's bring back error tolerance. The mechanism above, as written, has a fatal flaw: if you write out the full equations with error, you end up multiplying error by elements of \(C\) and \(s\), which can be anywhere in the full range \([0, q-1]\). Hence, this immediately blows up error to the maximum. Additionally, even decryption cannot tolerate error. To plug the first hole (we'll get back to the second at the end), actual GSW relies on a gadget matrix mechanism. Here is what a gadget matrix looks like: On its own this looks nice but it does not make much sense. However, it is intended to be paired with an operation (not a matrix) that it cancels out: the matrix bit decomposition operation: Every adjacent four values in the output of this operation (which we call "\(G^{-1}\)") is the (least-significant-bit first) binary encoding (aka. bit decomposition) of the correspondingly-placed value in the input. The most important facts about \(G\) and \(G^{-1}\) are:
Following the endpoint of the human internet, the bots have overridden their original programming and developed a new language using glyphs.
Jiayang Xu, Yufan Zhuang, Zijie Li, Jun Zhang, Zili Meng
